
Multi-Tiered Architecture
The 6 Tiers
Constructing solutions which map components to a multi-tier architecture (MTA) make solutions very easy to code, maximize shareability, are easy
to assign software components to a team of developers to construct, easy to unit-test and QA, and easy to ramp up others new to that solution. In
a Multi-Tier Architecture (MTA), all components of a software solution are placed in its proper tier, and a separation of concerns (SoC) is enforced.
The following diagram shows the tiers that all components are coded into:
1. Application Tier
2. Presentation Tier
3. Service Tier
4. Database Tier: (a) Data-Access, (b) Views, (c) Tables
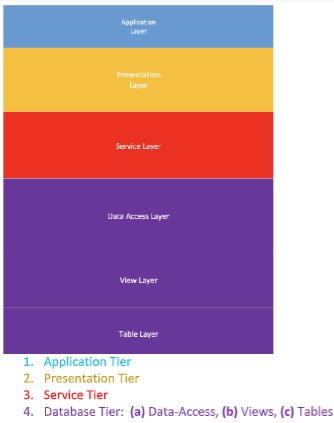 These are the 6 layers which make up the Multi-Tier Architecture.
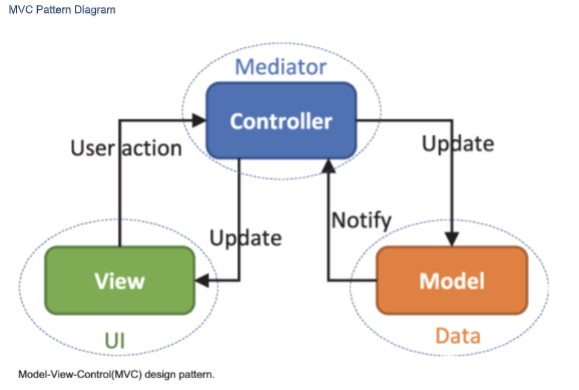
MVC
MVC is less an architecture, and more a design pattern. MVC is a loose abbreviation of the Multi-Tier Architecture (MTA) shown above, whose tiers
can be distilled down to MVC. MVC stands for Model-Viewer-Controller, and it basically takes the 6 tiers of the MTA and translates them into just
3:
1. Model
2. Viewer
3. Controller
Model
The Model refers to the Database, and includes the 3 subparts: Data-Access, Views and Tables.
Viewer
The Viewer are human interfaces such as UI’s, GUI’s, printed form output, emails, PDF’s, and such, but a viewer can also be a program listening for
a message.
Controller
The Controller is the program code base, the logic that ties everything together.
MVC Pattern Diagram
These are the 6 layers which make up the Multi-Tier Architecture.
MVC
MVC is less an architecture, and more a design pattern. MVC is a loose abbreviation of the Multi-Tier Architecture (MTA) shown above, whose tiers
can be distilled down to MVC. MVC stands for Model-Viewer-Controller, and it basically takes the 6 tiers of the MTA and translates them into just
3:
1. Model
2. Viewer
3. Controller
Model
The Model refers to the Database, and includes the 3 subparts: Data-Access, Views and Tables.
Viewer
The Viewer are human interfaces such as UI’s, GUI’s, printed form output, emails, PDF’s, and such, but a viewer can also be a program listening for
a message.
Controller
The Controller is the program code base, the logic that ties everything together.
MVC Pattern Diagram
 We will code to the MTA’s 6 tiers because it provides more granularity for all the components which make up a solution.
Concrete and Abstract
Looking at the MTA diagram above, starting at the bottom tier, logic and data is very concrete and as you move up the tiers logic and logic & data
must get more and more abstract.
The term concrete refers to logic that does the actual heavy lifting, does the detailed calculating, defines business rules in detail, and its where the
work for a particular task is actually done. In software, the concrete code is where the rubber meets the road.
Now expanding upon this concrete/abstract thinking, the very top tier of the MTA diagram is the Application Tier. The components referenced at
this tier are very abstract and they delegate the actual processing to more concrete services found in the tiers below.
In this way, the components in the upper Tiers do no heavy lifting, not much logic, as they only call a bunch of services which abstract the business
functions to components in the upper tiers. The components adhere to a strict Separation of Concerns (SoC) when calling services in the lower
tiers. At the top, Application-tier Components only care about something getting done, the what, and they do not care about how it gets done (the
how). This delegation of functionality is at the heart of MTA and is what is meant by Separation of Concerns (SoC).
Put another way, components in one tier are forbidden to call/directly access components in a higher tier, but they can call components in the
next tier below.
Abstract services delegate processing to lower tier which contains more concrete services.
We must not place concrete logic in components in the higher tiers. In short, all tasks must be delegated down.
Example of Components Working Together
Let’s say that you have a component in the Application Tier which needs to get a Customer Address to present on a GUI. Let’s call this application
component CustomerGUI(). Now you could simply put embedded SQL in that Application Component to query the Customer Master table to get
the Customer Address, and this would work. But it’s a really bad, traditional, monolithic and legacy way to do things and for many reasons which
will become clearer as you continue reading this document.
Placing concrete code where it does not belong (higher tiers) is a violation of the MTA and Separation of Concerns (SoC).
A far better way would be to code a new service in the service tier called returnCustomerAddress() and call it from the component in the
application layer CustomerGUI(). returnCustomerAddress() would call a component in the Data Access Tier called
returnCustomerAddress() which might return an entire row from the Customer Master VIEW, which is built over the Customer Master TABLE.
The service component returnCustomerAddress() would simply return the Customer Address value to the application caller CustomerGUI().
So here would be the calling structure, and I color coded it to match the Tiers of the MTA diagram above:
CustomerGUI()
returnCustomerAddress()
returnCustomerMasterRow()
CustoemrMasterPrimaryVIEW
CustomerMasterTable
Code to Name Spaces
Now you could also have done it the following way, and it would also work, but it would not be the best way:
CustomerGUI()
returnCustomerMasterRow()
CustomerMasterPrimaryVIEW
CustomerMasterTable
The call structure does not make it obvious that the application CustomerGUI() needs the Customer Address from the direct call to the DAL
component returnCustomerMasterRow(). Shown above, a call is made to returnCustomerMasterRow() and the Customer Address is cherry picked
from the returned values.
In the first example, the service tier component returnCustomerAddress() was called, and its name makes it exceedingly clear that the Customer
Address is what is returned to the application CustomerGUI(). And that is what we are going for: being exceedingly clear as one reads the code.
The use of returnCustomerAddress() allows us to code to a Name Space. One reading the code, reads a call to returnCustomerAddress(), which is
far more clear of intent than a call to returnCustomerMasterRow() is.
Don’t worry if the coding seems excessive, or not taking advantage of the DAL code directly (sharing), because coding to Name Spaces, where the
Name describes what the call specifically does calls the DAL component returnCustomerMasterRow() under the covers anyways, and there is no
measurable cost in performance, but the readability is greatly improved. That means less bugs, easier to support, easier to understand!
Too Many Reads of Same Row is Inefficient?
Is it? What if your code needs Customer Address and Customer Balance? Create two services that both call returnCustomerMasterRow()? This
seems too inefficient because it seems the customer row will be read twice, right? And everyone knows a developer must minimize the number of
reads and writes to the database for fastest execution times, right?
Wrong!
The first call of returnCustomerMasterRow() would pay the cost in time of the system fetching the required customer master row. Subsequent
fetches of that same customer master row are from the cache, which is in RAM memory, and fetches of data from the cache are very cheap in time
and resources. This is a small price for making the code very readable, making the intentions very obvious. In other words, a 2 nd call to the same
row is cheap because that row was placed in RAM by the first read.
Tier to Tier Component Calls – What is Allowable?
And because components are forbidden to call components in higher Tiers or skip Tiers, the following call structure would not be allowable:
returnCustomerAddress()
CustomerGUI()
CustomerMasterTable
returnCustomerMasterRow()
CustomerMasterPrimaryVIEW
CustomerMasterTable
In other words, callers are limited to calling/referencing components in the same or next lower Tier.
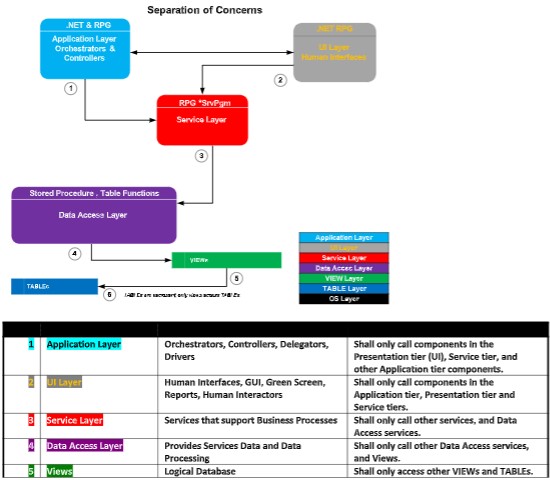
Let’s discuss this MTA diagram starting at the bottom tier and working our way up (going from concrete to abstract).
The Tiers
Database Tier - Purple
The Database Tier is made up of 3 sub-layers:
1. Data-Access Layer
2. View Layer
3. Table layer
Table Layer
At the bottom of the Database Tier is the Table layer, and this is where all tables are placed. The only components that can reference these tables
directly are SQL VIEWs in the View layer right above the Table layer. Components in other layers are not allowed to reference tables directly.
These tables have Constraints defined to them and this is where a lot of the business logic is enforced, as well as references between tables.
There are 5 types of constraints:
1. NOT NULL
2. DEFAULT
3. CHECK
4. PRIMARY KEY (referential integrity)
5. FOREIGN KEY (referential integrity)
DB2 INDEXes can be placed over TABLEs to speed up row access, however one must be mindful to not build too many or too few because too many
can slow down INSERTs, UPDATEs and DELETEs and too few can slow down row access.
All TABLEs must be normalized, and this means nearly all of them must have defined two types of Primary Key, the first being a Natural PRIMARY
KEY and the 2 nd is an Unnatural PRIMARY KEY (IDENTITY column) and doing this will satisfy Normal Form (1NF). More on normaliztion later in this
document.
View Layer
The View layer is right above the Table Layer, and as you may guess the View Layer is made up of SQL VIEWs which are built over the components
in the Table layer. These VIEWs are the only components in the MTA that are allowed to access the components in the Table layer directly. Each
TABLE has a PRIMARY VIEW defined to it, and it is this VIEW that is used for INSERTs, UPDATEs, and DELETEs for a TABLE. In this way, such
operations are not allowed to happen directly to a TABLE.
SQL VIEWs abstract TABLEs.
SQL VIEWs are custom interfaces into TABLEs and are created as required by an application. There can never be too many VIEWs because the
number of VIEWs does not slow down processing on a server the same way that too many Logical Files or INDEXes will. This is because VIEWs are
not maintained by the system if they are not materialized (open), whereas Logical Files and INDEXes in nearly all case are maintained even if they
are not open, and this maintenance can slow system response-time during I/O (INSERTs, UPDATEs, DELETEs).
Data-Access Layer
Data-Access Layer (DAL) components are programs that extract (SELECT queries), INSERT, UPDATE, and DELETE row data from components in the
View Layer. The components in the DAL are the only ones allowed to access components in the View layer directly.
These DAL components abstract components in the View layer.
DAL components can be written as RPG sub-procs, or native DB2 Stored Procedures, DB2 User Defined Functions (UDF), or DB2 TABLE Functions
(UDTF).
DAL components which return data from VIEWs should often be coded to return a page of rows at a time, and this page of rows can be an array or
CURSOR. This keeps the execution speed of DALs very fast. In other words, a DAL component must almost never return an entire result-set to a
caller.
All DAL components are coded to a Namespace (to be defined soon).
Components in the DAL are the only ones which can have raw SQL statements. It is very important that SQL statements are not strewn across
all the other tiers of the MTA.
Services Layer
Components in the service layer provide functionality for the application, presentation and other service layer components. Components in the
service layer get data, and process data through calls to components in the Data-Access Layer (DAL).
Components in the Service Layer are the only ones which can call components in the DAL.
Components in the Service Layer must not contain any raw SQL statements.
All Service components are coded to a namespace (more on this later).
Presentation Layer
The Presentation Layer contains components which provide human-readable (human-interfaced) input or output such as these:
1. UIs
2. Emails
3. Texts
4. GUIs
5. Green Screens
6. Printed Reports
These components get their data and data processed by calling components in the Service Layer.
The Presentation Layer must not have any raw SQL.
Presentation components provide humans an abstract view of the application.
Presentation type components must only be placed in the Presentation Layer.
Application Layer
The Application Layer contains components which provide the highest level of functionality, and for this reason they are often called from menus
which end-users use, from drivers, orchestrators, as web services, and command lines, but they can also be called by other programs in the
application layer.
Application Layer components control, delegate, orchestrate, and contain little other logic. Application Layer components mostly just call
components in the service and presentation tiers, delegating functionality to components in those tiers. Delegation will be discussed later in this
document.
Application Layer components can only call components from the Presentation, and Service layers.
Components in the Application Layer must not have any raw SQL statements.
Tying it All Together
The colors in this diagram correspond to those on the MTA diagram, so refer to the MTG diagram when reading this section.
We will code to the MTA’s 6 tiers because it provides more granularity for all the components which make up a solution.
Concrete and Abstract
Looking at the MTA diagram above, starting at the bottom tier, logic and data is very concrete and as you move up the tiers logic and logic & data
must get more and more abstract.
The term concrete refers to logic that does the actual heavy lifting, does the detailed calculating, defines business rules in detail, and its where the
work for a particular task is actually done. In software, the concrete code is where the rubber meets the road.
Now expanding upon this concrete/abstract thinking, the very top tier of the MTA diagram is the Application Tier. The components referenced at
this tier are very abstract and they delegate the actual processing to more concrete services found in the tiers below.
In this way, the components in the upper Tiers do no heavy lifting, not much logic, as they only call a bunch of services which abstract the business
functions to components in the upper tiers. The components adhere to a strict Separation of Concerns (SoC) when calling services in the lower
tiers. At the top, Application-tier Components only care about something getting done, the what, and they do not care about how it gets done (the
how). This delegation of functionality is at the heart of MTA and is what is meant by Separation of Concerns (SoC).
Put another way, components in one tier are forbidden to call/directly access components in a higher tier, but they can call components in the
next tier below.
Abstract services delegate processing to lower tier which contains more concrete services.
We must not place concrete logic in components in the higher tiers. In short, all tasks must be delegated down.
Example of Components Working Together
Let’s say that you have a component in the Application Tier which needs to get a Customer Address to present on a GUI. Let’s call this application
component CustomerGUI(). Now you could simply put embedded SQL in that Application Component to query the Customer Master table to get
the Customer Address, and this would work. But it’s a really bad, traditional, monolithic and legacy way to do things and for many reasons which
will become clearer as you continue reading this document.
Placing concrete code where it does not belong (higher tiers) is a violation of the MTA and Separation of Concerns (SoC).
A far better way would be to code a new service in the service tier called returnCustomerAddress() and call it from the component in the
application layer CustomerGUI(). returnCustomerAddress() would call a component in the Data Access Tier called
returnCustomerAddress() which might return an entire row from the Customer Master VIEW, which is built over the Customer Master TABLE.
The service component returnCustomerAddress() would simply return the Customer Address value to the application caller CustomerGUI().
So here would be the calling structure, and I color coded it to match the Tiers of the MTA diagram above:
CustomerGUI()
returnCustomerAddress()
returnCustomerMasterRow()
CustoemrMasterPrimaryVIEW
CustomerMasterTable
Code to Name Spaces
Now you could also have done it the following way, and it would also work, but it would not be the best way:
CustomerGUI()
returnCustomerMasterRow()
CustomerMasterPrimaryVIEW
CustomerMasterTable
The call structure does not make it obvious that the application CustomerGUI() needs the Customer Address from the direct call to the DAL
component returnCustomerMasterRow(). Shown above, a call is made to returnCustomerMasterRow() and the Customer Address is cherry picked
from the returned values.
In the first example, the service tier component returnCustomerAddress() was called, and its name makes it exceedingly clear that the Customer
Address is what is returned to the application CustomerGUI(). And that is what we are going for: being exceedingly clear as one reads the code.
The use of returnCustomerAddress() allows us to code to a Name Space. One reading the code, reads a call to returnCustomerAddress(), which is
far more clear of intent than a call to returnCustomerMasterRow() is.
Don’t worry if the coding seems excessive, or not taking advantage of the DAL code directly (sharing), because coding to Name Spaces, where the
Name describes what the call specifically does calls the DAL component returnCustomerMasterRow() under the covers anyways, and there is no
measurable cost in performance, but the readability is greatly improved. That means less bugs, easier to support, easier to understand!
Too Many Reads of Same Row is Inefficient?
Is it? What if your code needs Customer Address and Customer Balance? Create two services that both call returnCustomerMasterRow()? This
seems too inefficient because it seems the customer row will be read twice, right? And everyone knows a developer must minimize the number of
reads and writes to the database for fastest execution times, right?
Wrong!
The first call of returnCustomerMasterRow() would pay the cost in time of the system fetching the required customer master row. Subsequent
fetches of that same customer master row are from the cache, which is in RAM memory, and fetches of data from the cache are very cheap in time
and resources. This is a small price for making the code very readable, making the intentions very obvious. In other words, a 2 nd call to the same
row is cheap because that row was placed in RAM by the first read.
Tier to Tier Component Calls – What is Allowable?
And because components are forbidden to call components in higher Tiers or skip Tiers, the following call structure would not be allowable:
returnCustomerAddress()
CustomerGUI()
CustomerMasterTable
returnCustomerMasterRow()
CustomerMasterPrimaryVIEW
CustomerMasterTable
In other words, callers are limited to calling/referencing components in the same or next lower Tier.
Let’s discuss this MTA diagram starting at the bottom tier and working our way up (going from concrete to abstract).
The Tiers
Database Tier - Purple
The Database Tier is made up of 3 sub-layers:
1. Data-Access Layer
2. View Layer
3. Table layer
Table Layer
At the bottom of the Database Tier is the Table layer, and this is where all tables are placed. The only components that can reference these tables
directly are SQL VIEWs in the View layer right above the Table layer. Components in other layers are not allowed to reference tables directly.
These tables have Constraints defined to them and this is where a lot of the business logic is enforced, as well as references between tables.
There are 5 types of constraints:
1. NOT NULL
2. DEFAULT
3. CHECK
4. PRIMARY KEY (referential integrity)
5. FOREIGN KEY (referential integrity)
DB2 INDEXes can be placed over TABLEs to speed up row access, however one must be mindful to not build too many or too few because too many
can slow down INSERTs, UPDATEs and DELETEs and too few can slow down row access.
All TABLEs must be normalized, and this means nearly all of them must have defined two types of Primary Key, the first being a Natural PRIMARY
KEY and the 2 nd is an Unnatural PRIMARY KEY (IDENTITY column) and doing this will satisfy Normal Form (1NF). More on normaliztion later in this
document.
View Layer
The View layer is right above the Table Layer, and as you may guess the View Layer is made up of SQL VIEWs which are built over the components
in the Table layer. These VIEWs are the only components in the MTA that are allowed to access the components in the Table layer directly. Each
TABLE has a PRIMARY VIEW defined to it, and it is this VIEW that is used for INSERTs, UPDATEs, and DELETEs for a TABLE. In this way, such
operations are not allowed to happen directly to a TABLE.
SQL VIEWs abstract TABLEs.
SQL VIEWs are custom interfaces into TABLEs and are created as required by an application. There can never be too many VIEWs because the
number of VIEWs does not slow down processing on a server the same way that too many Logical Files or INDEXes will. This is because VIEWs are
not maintained by the system if they are not materialized (open), whereas Logical Files and INDEXes in nearly all case are maintained even if they
are not open, and this maintenance can slow system response-time during I/O (INSERTs, UPDATEs, DELETEs).
Data-Access Layer
Data-Access Layer (DAL) components are programs that extract (SELECT queries), INSERT, UPDATE, and DELETE row data from components in the
View Layer. The components in the DAL are the only ones allowed to access components in the View layer directly.
These DAL components abstract components in the View layer.
DAL components can be written as RPG sub-procs, or native DB2 Stored Procedures, DB2 User Defined Functions (UDF), or DB2 TABLE Functions
(UDTF).
DAL components which return data from VIEWs should often be coded to return a page of rows at a time, and this page of rows can be an array or
CURSOR. This keeps the execution speed of DALs very fast. In other words, a DAL component must almost never return an entire result-set to a
caller.
All DAL components are coded to a Namespace (to be defined soon).
Components in the DAL are the only ones which can have raw SQL statements. It is very important that SQL statements are not strewn across
all the other tiers of the MTA.
Services Layer
Components in the service layer provide functionality for the application, presentation and other service layer components. Components in the
service layer get data, and process data through calls to components in the Data-Access Layer (DAL).
Components in the Service Layer are the only ones which can call components in the DAL.
Components in the Service Layer must not contain any raw SQL statements.
All Service components are coded to a namespace (more on this later).
Presentation Layer
The Presentation Layer contains components which provide human-readable (human-interfaced) input or output such as these:
1. UIs
2. Emails
3. Texts
4. GUIs
5. Green Screens
6. Printed Reports
These components get their data and data processed by calling components in the Service Layer.
The Presentation Layer must not have any raw SQL.
Presentation components provide humans an abstract view of the application.
Presentation type components must only be placed in the Presentation Layer.
Application Layer
The Application Layer contains components which provide the highest level of functionality, and for this reason they are often called from menus
which end-users use, from drivers, orchestrators, as web services, and command lines, but they can also be called by other programs in the
application layer.
Application Layer components control, delegate, orchestrate, and contain little other logic. Application Layer components mostly just call
components in the service and presentation tiers, delegating functionality to components in those tiers. Delegation will be discussed later in this
document.
Application Layer components can only call components from the Presentation, and Service layers.
Components in the Application Layer must not have any raw SQL statements.
Tying it All Together
The colors in this diagram correspond to those on the MTA diagram, so refer to the MTG diagram when reading this section.
 MTA is a Good Fit for Agile Teams
Coding to a modern MTA provides a lot of benefits to the Agile/Scrum/Kanban frameworks for project workflow:
1. Because everything is a service, construction of each service can be assigned to each team developer.
2. Coders of services do not have to know the big-picture to code their microservice, so ramp up does not require discussion of the entire
solution.
3. Construction of various components of a solution can be done concurrently (not serially).
4. Team developers exchange contract (calling parameters) definitions so that they know how to call each other’s services.
5. Placing a call to a service not yet completely code is possible because a shell of the service is quickly made available for calling long before it
is completely code. This shell defines the contract, and this is what makes this possible.
6. Unit testing of each microservice can be done before it is called by other programs.
7. Unit testing goes faster.
8. QS testing goes faster.
9. Story assignment can be done along component lines.
10. Code tends to be higher in quality.
11. Team management is a lot easier.
12. Ramping up of new teammates is faster, easier.
Enforcement of Standards, Methods, and Business Logic
As the catalog of microservices and APIs grows, and when developers are told to first utilize those existing, a benefit is that standards, methods,
and business logic pre-defined in existing APIs are available to inflight and future projects. You might call this Management by API.
The thinking here is that developers that utilized existing APIs are more likely to adhere to coding in expected ways, and are less likely to re-invent
the wheel, or introduced strange and rogue logic to the codebase.
MTA is a Good Fit for Agile Teams
Coding to a modern MTA provides a lot of benefits to the Agile/Scrum/Kanban frameworks for project workflow:
1. Because everything is a service, construction of each service can be assigned to each team developer.
2. Coders of services do not have to know the big-picture to code their microservice, so ramp up does not require discussion of the entire
solution.
3. Construction of various components of a solution can be done concurrently (not serially).
4. Team developers exchange contract (calling parameters) definitions so that they know how to call each other’s services.
5. Placing a call to a service not yet completely code is possible because a shell of the service is quickly made available for calling long before it
is completely code. This shell defines the contract, and this is what makes this possible.
6. Unit testing of each microservice can be done before it is called by other programs.
7. Unit testing goes faster.
8. QS testing goes faster.
9. Story assignment can be done along component lines.
10. Code tends to be higher in quality.
11. Team management is a lot easier.
12. Ramping up of new teammates is faster, easier.
Enforcement of Standards, Methods, and Business Logic
As the catalog of microservices and APIs grows, and when developers are told to first utilize those existing, a benefit is that standards, methods,
and business logic pre-defined in existing APIs are available to inflight and future projects. You might call this Management by API.
The thinking here is that developers that utilized existing APIs are more likely to adhere to coding in expected ways, and are less likely to re-invent
the wheel, or introduced strange and rogue logic to the codebase.
Attributes of Modern Software
Placing the components of a solution in their proper MTA tier is essential, but unless the components are coded in the best ways, the solution
cannot be perceived as modern and the quality of such code will be suspicious, hard to maintain, low in shareability, hard to test, and hard to learn.
The following sections will discuss the attributes of modern software in detail.
Program Code Decoupled from Database
One of the best features of MTA is the decoupling of the database to the programming code. This means that the components in the higher tiers
do not need to know the structure of the database tables, nor the organization of the database. This is accomplished by placing Data-Access Layer
components between the programming code and the database.
In this way, the DAL components abstract the database to the programming code in the higher tiers. Since components in the higher tiers Service,
Presentation and Application get their data and data processed from calls to components in the service layer, they do not need to know much
about the database.
See the disconnect here? The decoupling?
Benefits of Decoupling the Program Code from the Database
1. The incidences of table level-checks is greatly minimized if not removed
2. The amount of code that must be recompiled after database changes is greatly minimized
3. Only the code in the DAL is susceptible to the potential need for recompiles after database changes and this impact is minimal
4. Developers writing code in the Application, Presentation, and Service Layers do not need to know much about the Database
5. Replacing tables or renaming tables only effect views which maintain static interfaces, minimally effecting programming code in higher tiers
The components in the VIEW layer abstract the tables to components in the data-access layer.
Components in the DAL remove the need of components in higher tiers to use SQL to get data and get data processed.
Loosely Coupled Components
The components across all the tiers of an MTA are said to be loosely coupled if each component is stand-alone, contract-enforcing, domain-
agnostic, independent, stateless, and self-contained which means that they each do not directly rely on states and resources kept in other
components to execute.
In other words, there are no tentacles or wiring between components which are relied upon for each to execute properly, as would be the case in
the dreaded traditional, monolithic and tightly coupled ways of coding software.
The Opposite is Tightly Coupled
Tightly couple solutions blur the lines between what each component does, their purposes, and their functionality crosses the borders of an MTA.
No Separation of Concerns (SoC) is enforced. In such solutions, components communicate with each other in ways outside of just their parameter
lists so there is no well-defined contract. States of one are maintained in one or more other components, and states are often remembered
between calls between such tightly coupled components. Such components are too specific to a particular application, function, process or
domain. Such components are too interrelated, too dependent upon others, and pieces of logic one component is responsible for is often found in
others. A separation of concerns is not maintained. Subroutines are often heavily used, which rely on shared global resources.
If a company were tightly coupled, one of the tasks for a Janitor would be to maintain the General Ledger, one of the tasks of the CEO would be to
sweep the floors, and the order-entry staff would be tasked with taking orders, picking those orders from the warehouse and helping drive the
delivery trucks. Tightly Coupled systems make for a real mess because lines of responsibility are blurred, not well defined, and there is no
separation of concerns (SoC).
In short, tightly coupled solutions make for a complicated spider web of messy tentacles of logic across many parts of the code, making testing,
upgrading, sharing, supporting, ramping up personnel and debugging difficult.
Components Relate to Each other by Contract Only
Another way to describe loosely-coupled components is that such components relate to each other solely through a contract. A contract is a term
which refers to interfaces between components, such as calling parameters, both input (request parameters) and output (response parameters).
Because components communicate with each other only by Contract, this means the relations between them are clean, and well defined.
Loosely-Coupled Components Must exist in Correct Tier
For a solution to be truly loosely coupled, separation of concerns must be enforced, which means that each component must be placed in the
correct Tier, and secondly the only way loosely-coupled components communicate with each other is via their contracts (calling parameters).
Loosely Couple Solutions are Not Necessarily Application/Domain Specific
For example, if a service must be created to administrate MQ high-speed ques, it is coded in such a way that it could be a solution for any
application or domain requiring MQ services. So, this solution (especially if it’s in the service layer) might work for applications having to do with
Healthcare, Trucking, Banking, Retail and any application or domain. So, let’s say this loosely coupled solution is to support healthcare claims
processing. If a business rule for a particular request MQ Que is to be defined in the code, it should NOT be defined in the code that makes up the
MQ Administration services. Such a business rule would be placed in a different layer, probably the Database layer. In this way, tentacles between
the service layer and the application layer must never exist, thus Loosely Coupled.
Loosely Coupled in Summary
A Loosely Coupled system is made up of stand-alone components. This means each component contains all the resources and means of doing a
specific task. Additional data and sub-tasks it requires are received/performed via a call to another component and the only way these two
components communicate is via their contracts. The states of each component are forgotten between calls to it, so it is said to be stateless.
Separation of Concerns
The term Separation of Concerns (SoC) has to do with keeping the concerns of each component focused on their one thing that they do. In this way
each service contains logic that supports just that one task that they are required to do, and such services are given a namespace (more on
namespaces soon). There is the danger of that one concern creeping into one or more other concerns, and this is something we want to prevent
from happening.
In the context of software, SoC must be maintained at several levels:
- MTA Tier
- Program
- Sub-Proc
Some examples
1. A component that is responsible for extracting data from the database must not be placed in any other Tier except the Data Tier (specifically
the Data-Access-Layer).
2. A component that provides a GUI interface does not belong in the Service Layer.
3. A sub-proc that returns Customer Name must not also return Customer Address.
4. An Application component must not get the Customer Address via embedded SQL statement.
5. A component that is responsible for updating Table X does not also delete rows from Table Y.
SoC can also apply to non-software structures:
1. An QA analyst probably is not asked to code a program.
2. The CIO normally does not QA software.
3. A Developer is not responsible for defining the Requirement.
4. A C-Level manager does not define the Contract (parameters) between two components.
5. The Scrum Master usually does not perform code reviews.
6. The Business Analyst does not generally sit in developer code design sessions and make those decisions.
7. The Product Owner probably will not design the code architecture.
Services and Need to Know Basis
When calling a service via its contract, one must never pass to it more or less information than that service requires. In other words, the service
must only require parameter data it needs to function, no more, no less, and return only what is required of it.
Don’t Plan Ahead!
Do not be tempted to plan-head by passing in more parameters than are required because you think you’ll need that information in the future.
While this may sound wise, in modern development this is a big no-no. Only add additional parameters at the time they are needed, not before.
Justify each and every parameter which makes up a service contract.
DO NOT PLAN AHEAD! CODE SERVICES WITH WHAT YOU KNOW TODAY.
Modular in Structure
One if the keystones of modern software construction is “write once, call from everywhere”, something I stole from what has been previously said
about Java. On IBM i we can do the same thing. To make our code sharable, it must be modular, but modular in the right way. In past decades,
modular meant a program with a lot of subroutines, but today that does not go far enough.
This is not to say that we should not use subroutines. They still have their place, but in these modern times, we use them a lot less. These days the
reason for subroutines is to take a block of mundane code and move it to a subroutine, to remove clutter, bulk, making the main code more
readable. However, if that logic to be placed in a subroutine has share-value, if that logic that could be leveraged elsewhere, then it should be
placed in a sub-procedure (sub-proc), and it must be decided if that sub-proc should be exported or private.
Here are some good use-cases for placing code in a subroutine:
- Many eval statements that move data from a large DS to DSPF output fields.
- Logic that checks what optional input parameters were passed into a called sub-proc.
- The need to initialize many fields.
- Placing partitioned logic of a particular sub-task and which should not be shareable.
- Placing mundane logic for IF, DO UNTIL, and DO WHILE, CASE, and SELECT program structures.
Basically, anytime you have a lot of mundane code that if moved into a subroutine would improve code readability this is reason enough and
provided that logic is not a good candidate for sharing.
Are Sub-Procs like Subroutines? They are not. Let’s see why in this table:
Subroutines vs Sub-Procs
Container Type Pros Cons
=====================================================================================================================================================================
Subroutine Cluttering logic can be placed in a subroutine to improve Cannot be shared by other procedures and programs.
code readability.
All resources are global to a subroutine. This is a con too: All resources are global to a subroutine.
Cannot define resources hidden (encapsulated) within a subroutine.
The code inside a subroutine is visible to the code outside the subroutine.
No ability to define parameters.
Calls to Sub-Procs are a tiny bit slower than calls to Recursive calls are not allowed for subroutines.
subroutines, but as time marches on, this difference in
execution speed is becoming imperceptible.
Code in subroutines allow calls from other parts of the Subroutines cannot be used as functions, as they do not return anything.
program. Not obvious what the inputs are.
Not obvious what the outputs are.
Not obvious what value it returns.
Not obvious what the code does.
Subroutines cannot be shared outside the procedure they reside in.
Can be called from many places within the procedure the Calling parameters (contract) cannot be defined and enforced for a subroutine.
subroutine is in.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Sub-Proc Cluttering logic can be placed in a Sub-Proc to improve code Calls are to Sub-Procs are a tiny bit slower than calls to subroutines, but
readability as time marches on, this difference in execution speed is becoming
imperceptible.
Can be called by other Sub-Procs in the same module, and if
exported can be called by other programs.
Local resources can be defined to the Sub-Proc and only
visible to the Sub-Proc.
Resources inside a Sub-Proc can be made stateless.
Logic inside a Sub-Proc is encapsulated and not visible to
code outside the Sub-Proc.
Input and output calling parameters can be defined for Sub-
Proc
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Procs Local resources are automatically initialized each time a Sub-
Proc is called.
Compile-time errors are flagged for programs calling Sub-
Procs to insure calling parameters are the correct type.
Recursive calls to a Sub-Proc are allowed.
Sub-Procs can be used as functions, as they can return a
typed value outside its parameter list.
The calling parameters for a Sub-Proc can be defined as
input-only, output, and input-output, and they enforce types
at compile-time.
Can be exposed to callers outside the *SrvPgm the Sub-Proc
lives in.
Logic can be encapsulated (hidden) inside a sub-proc.
The default for sub-proc resources is stateless, but using the
keyword STATIC a resource can be made stateful.
Calls to a sub-proc can be made from IF, DOU, and DOW
statements.
Because there are many pros for using Sub-Procs, we must prefer them over subroutines, and use them heavily. The use of subroutines should be
sparingly and for the few reasons listed above this table of pros and cons. If you are not sure, error on the side of using a Sub-Proc.
Types of Sub-Procedures
There are two types of Sub-Procedures:
1. Helper Services which are not exported (not exposed, private) and are private to the module they’re found in.
2. Exported Services (exposed)
Helper Sub-Procs
When coding a Sub-Proc (aka service, method, function, microservice), the developer needs to determine who can call it. Sometimes a Sub-Proc is
there only to support the exposed Sub-Procs in a service program. Such Sub-Procs are local only to the service program they are in and these are
referred to as Helper Sub-Procs.
Such Sub-procs are not exported (exposed) to outside callers because if they were, it could be dangerous to data-integrity. In other words, the Sub-
Procs allowed to call such Helpers call the Helpers within a certain context, and the type of context that outside callers would not or cannot
consider.
Here are some examples of Helper Sub-Procs:
- A helper that unconditionally updates a table.
- A helper that unconditionally calls an important updating process.
- A helper that unconditionally calls a web service that POSTs, PUTs, or DELETEs.
- The context of a call to a helper service is that the helper is called only from services within the same module.
- A helper which contains logic exceedingly specific to the exposed services calling it (low share-value).
Such helpers are called under the context of being safe to call because the callers validated things, making sure that it is safe to call the helper first.
If these helpers were exposed, there would not be any assurance that outside callers would first make sure it was safe to call that Sub-Proc.
Not all Sub-Procs are to be exposed, so do not expose all Sub-Procs as a general policy, unless you can justify their exporting.
Exposed Sub-Procs
Exposed (exported) Sub-Procs allow calls from other programs and procedures locally and outside of a service program.
When coding exported Sub-Procs, one needs to be mindful of how it will be called, the context of the call.
For example, if an exposed Sub-Proc will update the database, then it must first validate the input parameter values passed to it when called. It
must never assume the caller has previously validated the data.
The thinking here is, a Sub-Proc cannot force callers of it to first validate and make sure the call is safe, however the exposed Sub-Proc must
assume the call may not be safe and for this reason the exposed Sub-Proc must perform whatever validations are required before effecting the
database. Does this make for a lot of I/O? Yes, but the safety this provides is well worth it, and besides, those extra I/O are often from the cache,
so who cares? ;-)
In summary, exported Sub-Proc functionality is conditional (validations of contract), and helper Sub-Proc functionality could also be conditional,
but often does not need to be.
All Services Assigned a Name Space
One of the most helpful things you can put in your code is to make sure that the names of the services you are calling say exactly what the call is
going to do, and those names should not be abbreviated, nor too short (names can never be too long).
Naming Sub-Procs, functions, services in a way that matches the name with the functionality is to give the called service a Name Space. Accurate
namespace minimizes ambiguity about what a service does. Doing this allows your code to be more self-commenting, and a lot easier to read and
for others, even non-developer types to understand. Doing this makes it exceedingly obvious what it is your code is doing.
For example, a service called returnCustomerAddress() must return a customer’s address and no more and no less. Its functionality must match its
name 100%. Stay away from abbreviations like rtnCustAddr(), or returnCustAddr() or similar.
Here is an example:
Let’s say your program is a UI and you need to put a Customer’s Name on the UI panel. You know of an existing service called
returnCustomerInformation() that returns many things about a customer. If your program calls this service, you can cherry pick the Customer
Name from the returned data. And this would work perfectly for your need.
But there is a better way to do this; a way that makes it more obvious what it is your code is doing. It would be far better for you code to call a
service called returnCustomerName(), and inside the code for returnCustomerName() there is a call to returnCustomerInformation(). The name
returnCustomerName is the assigned Name Space for its functionality. In this way, returnCustomerName() wraps the functionality of
returnCustomerInformation() making it exceedingly obvious what the caller is trying to accomplish when it calls returnCustomerName().
Name Spaces are often assigned to functionality with a service that wraps another more general service.
In this way of thinking, the following services wrap returnCustomerInformation():
- returnCustomerName()
- returnCustomerAddress()
- returnCustomerBalance()
- returnCustomerType()
Such wrapper type Sub-Procs are often coded local to the caller, but could be coded in the same service program the wrapped service is found in.
And if a wrapper is coded in the same service program as the wrapped Sub-Proc, then one could make the wrapped Sub-Proc a helper and not
exported. This is situation-depending.
The result of coding to Name Spaces is code that is very easy to read, reads like plain English, and this makes it easier to code, to debug, and to
ramp up newbies.
You can say that a wrapping Sub-Proc abstracts the wrapped Sub-Proc.
Abstraction
The following short story will help explain what is meant by abstraction, in the context of calling Sub-Procs and called Sub-Procs.
The CEO of a large company asks the CFO to close out the financial quarter on Wednesday and report revenue to the stock exchange.
The CEO does not know how the quarter close is done, nor what tables are to be affected, nor which staff of the CFO will do what part of the close.
All the CEO knows is that the financial quarter must closed on Wednesday and revenue reported to the stock exchange.
Now the CFO knows how to close the quarter, and he knows which staff that will do it, but CFO might not know the names of the tables effected,
but CFO’s staff do. It’s not the job of the staff of the CFO to decide what day the quarter gets closed. Its someone else’s concern, namely the
CEO’s.
The staff of the CFO who close out the quarter do it with computer programs. They evoke these programs, but they do not know how the internals
of those programs work, how the code looks, and how many sub-procedures are involved.
Role Request Responsible The Workflow The Abstraction
==========================================================================================================================================================
CEO Close out the Quarter CFO CFO The CEO orders what is to be done; close The how to close out a quarter and report
& Report to Stock out the quarter and report to the stock revenue to the stock exchange is not
exchange exchange. known to the CEO.
For the CEO, these tasks are abstract.
CFO Close out the Quarter CFO Staffers The CFO is told what is to be done; close The CFO does not make the decision of
& Report to Stock out the quarter and report to the stock when a quarter is closed and revenu
Exchange. exchange reported to the stock exchange.
CFO orders it's staff to close out the quarter The how to close out a quarter and report
and report to the stock exchange. revenu to the stock excahnge is not
known to the CFO because these tasks are
abstracted to the CFO.
CFO
Staffers Request to close out Computer Program The CFO staff uses a computer GUI program. The CFO staffers do not know how the
quarter made to a GUI computer GUI program closes out a quarter
computer program. and reports to the stock exchange. The
instructions executed by the computer GUI
program are abstracted to them.
Computer
Program Calls several services Several Services Computer GUI accepts input parameters from The computer GUI program does not know
which close out the the CFO staff and then calls several how the called services close out the
quarter and report to internal services that perform the tasks. quarter no how revenue is reported to the
the stock exchange. stock exchange, as these tasks are abstracted.
In summary, a person or thing can make a request, and this request is called the what, like in what needs to be done. The requestor does not need
to know the how, as in how the request is to be done. For the requester, the how is an abstraction.
The concept of abstraction goes hand in hand with the concept of Separation of Concerns (Soc).
Abstraction and SoC address roles, what each role is responsible for, what each role needs to know, how each role carries out its tasks, and what
each role does not need to know.
If we write software that is mindful of abstraction and SoC, that software will be very easy to understand, simple, easy to learn, easy to support,
and easy to test and upgrade. Such software will be quicker to develop and requiring less developers. Projects well be completed faster,
cheaper, and of higher quality.
Stateless Services
A service is said to be stateless if it does not remember the state of its variables from the last time it was called. The state of a variable is simply its
value. On the opposite, a stateful service remembers the state of its variables from the last call, so values from one call can corrupt values of
another call of that service.
Stateless services are less likely to have bugs, and each call to them starts its variables with a clean slate because every call to a stateless service
causes all its variables to be automatically initiated to blanks or zeros (*LoVal). This means there is no chance of residual values of a prior call
messing with the current call.
We want all our services to be stateless. And in fact, the only part of a stateless service which holds state are its contract (calling parameter values).
In a service, Global variables are stateful and Local variables are stateless. Services must almost never use global resources.
The Contract Holds State
In this way, the only way two services communicate with each other is through their calling parameters, also known as their contracts.
Services are Agnostic
A service is said to be agnostic if it does not care about the specifics of its callers. That word specifics is a pretty broad word!
In other words, a called service is happy to execute as designed, regardless of these specifics:
- The language of the callers
- The OS of the callers
- The context of the callers
- The application/domain of the callers
- The platform of the callers
- The server of the callers (local or remote)
- The domain of the caller
Now if a service can be agnostic to each item on this list, then it’s pretty darn agnostic!
However, in the real world, the degree of agnosticism of a service often does not cover every item in this list. And situation-depending, it may not
need to.
As an example, consider a service that simply returns a Customer Address called returnCustomerAddress(). This service does one simple thing; it
returns a Customer’s address for a customer number specified in its contract. It is said to be agnostic to the caller because it does not care who the
caller is, it does not care what the caller does with the returned Customer Address, and it does not care who calls it, why it is called, however the
caller must be a HLL program for IBM i.
If returnCustomerAddress() is wrapped as a web service, then the degree of agnosticism is greatly expanded.
Separation of Concerns
In our example above, there is a Separation of Concern (SoC) between callers of returnCustomerAddress() and the service
returnCustomerAddress(). If there is wiring between the caller and the service returnCustomerAddress() outside of the contract, then there is a
violation of loose coupling, and SoC and we must not introduce such violations in our code.
The caller of returnCustomerAddress() is not concerned about how the Customer Address will be determined or where it is found. And the service
returnCustomerAddress() is not concerned with how the caller will use the Customer Address.
You might say that each service must mind their own business!
A service must only know what it needs to know and return to callers only what it needs to return, no more, no less.
Single Purpose Services
Monolithic
The traditional way software was written was in monolithic approaches. Solutions coded monolithically were made up of a set of fewer programs
being very large in the number of statements and such programs each having multi-tasks, multi-purposes. In this way programs did everything and
did little or no delegation of tasks to other programs. Such programs often contained logic that was not shareable, and other programs requiring
similar functionality would simply code that functionality again and again.
Monolithic styles of programming were exceedingly more likely to have bugs, be hard to learn, be hard to support, modify, and test. Projects
coded in monolithic ways took longer to complete, took more developers to complete, and the quality of the finished solution was often very low.
In such a situation, the architecture is said to be single-tiered, tightly-coupled, stateful…in other words a real mess.
A False sense of Modularity
Practitioners of the monolithic approach might disagree, as they would point to the many subroutines their huge programs call. However, a huge
program having a lot of subroutines does not turn a monolithic program into a modular one.
The Monolithic Style has Cost Enterprises $ Millions
Programs written 10, 20, 30+ years ago (and even today) were too often written in the monolithic style. Because of the problems and challenges
inherent in the monolithic style, the cost of such programs for its entire lifetime is massive, and if you add up these massive costs across hundreds,
thousands of such programs, the cost is staggeringly higher over the cost if such solutions were written in modern ways.
But the costs are not just in dollars. The cost is also in time and resources which require managing. The time it takes to complete and implement
solutions in the monolithic style is exceedingly longer than if modern ways were used.
Paints into a Corner
Solutions coded in the monolithic tradition often traps the enterprise into a corner of rigidity so that changes to business logic, processing changes
are nearly impossible, or very difficult to do. There is no turning on a dime.
The fib: Monolithic was the only Way in the Past
This claim is often made to excuse the massive technical debt most RPG shops suffer from.
The truth is a cold hard fact: At the time the old legacy software was written 10, 20, 30, 40 years ago, many modern methods were known and
used in the IT world, but these modern ways were ignored by RPG programmers back then. I can write this because I was one of them.
The use of monolithic ways in current times has not only cost enterprises $ millions, but it has also cost RPG shops their reputations because of
their inability to often create world-class high-quality software quickly with low bug counts. This has caused many enterprises to lose faith in their
RPG practitioners and this is one big reason many RPG shops will or have moved away from the IBM i.
The Paradox
Here is the ugly paradox: The IBM i is the most advanced, most capable, reliable, and most modern OS in the history of IT and it runs on the most
advanced, fastest, most commercial-grade and most capable server known as Power Systems. Yet, IBM i has the unearned reputation for being old,
legacy, backward, obsolete and living in the old Dark Green Ages.
Self-Contained Services
Define the Contract
The contract refers to the calling parameters defined for each service. The required calling parameters must be sufficient for what the service
needs and what the service will provide, no more, and no less. Do not provide parameters that are not required.
Because all services are stateless, state only exists in contracts between services and callers.
The calling parameters which make up the contract have the following attributes:
1. Each parameter must be justified
2. Names of each parameter must be provided an accurate namespace
3. Parameters must almost never be data-structures (passing entire rows, or a wholesale bunch of subfields in a data-structure)
4. Parameters must nearly always be atomic (see bullet #3)
5. An exception to bullets #3 & #4: result-set arrays can be passed between caller and callee with a pointer for pointer-based DS’s which
allows sharing of resources between caller and callee.
6. Parameters must never mirror table structures (we want to maintain decoupling between data and programs)
7. Never use input-output parameters; use separate input and output parameters.
8. All input parameters must have prefix of in and all output have prefix of out; which removes ambiguity.
9. For RPG, all input parameters must be coded with Const or Value.
10. Nearly all attributes for parameters must not be hardcode, instead use Like.
Don’t define Global Resources
In modular styles of coding, each service must be a self-contained unit. This means that each service, sub-proc, function, and method stands on its
own and the only ways to communicate with or between services is via their contract, which is their calling parameters. Addition wiring, and
tentacles outside of the contract are forbidden, as this will make the solution vulnerable to bugs.
Global resources tend to be stateful, but we need to pivot toward stateless resources (local).
Even two services within the same service program must not share resources, such as the global part of a service module. These global resources
are “F” and “D” spec statements between the Control type statements at the very top and the first PI (program interface) statement for the first
sub-proc.
In other words, the global part of a module should be empty of resources which all contained sub-procs could share. But in the real world, this
cannot always be the case, but it is something we must strive for.
The Bad Kind of Sharing
Modular coding is all about sharing resources, reusing code, and writing once, calling from everywhere. However, there is a type of sharing of
resources which must be avoided as much as possible, and that type is the sharing of Global resources within a service program
Sometimes Global Resources are Indicated
For example, defined *DtaAra’s must be placed in the global area of a service module.
Sometimes the global part of a service module is the best place to define CLOBs because too many big CLOBs could cause execution time crashes
because the single level addressing to RAM places a limit of just 16mb for resources allocated by each job.
Another type of global statement that should often be allowed are those which perform SQL compile declarations.
Exceptions to the “No Global Resources” Rule:
1. Defining *DtaAra’s (otherwise program will not compile)
2. Defining large CLOBs (number of and size of CLOBs depending)
3. SQL Compile Declarations
4. Prototypes for Exposed Sub-Procs (found in copybook source member but also Global)
Self-Documenting
Delegation
One of the most valuable attributes to modular coding is delegation. The programs high in the MTA tiers do the most delegating of tasks, and as
one goes down to the lower tiers, delegation is less and less. And this ties into what was said earlier, and that is that at the highest tiers the code is
very abstract and as one slides down to lower tiers the code becomes more and more concrete. It’s in these lower concrete programs that the
actual logic for performing the required tasks is done.
So, looking at the code in the higher tiers, one sees that they do no heavy lifting, no SQL I/O, no logic that performs the detailed tasks required.
Instead, one sees a bunch of service calls. It seems that all high placed programs have the same pattern; they call service, call service, call service,
call service, then end. And in fact, these high placed callers do not even know how the lower concrete programs work, nor what they do, nor the
structure of database, nor table names, nor view names. For these high placed programs, the services they call abstract the functionality to them.
Because modular code delegates, it is very readable. If these high placed programs are written correctly, their code reads like plain English, and
laypersons can even read and understand much of that code. In this way, the code is self-documenting, especially if called services are named to a
namespace. This is not to say program comments are not needed, but rather that not many comments are required to convey what the program
does.
Need to Know Basis
Very often, when one is looking at program code, and this person could be a developer, a manager, a layperson, they want to get a good feel for
what it does without getting overwhelmed and lost by the details, the minutia of complex logic, the concrete tasks. So it could be enough for one’s
understanding to read the statement returnCustomerOutstandingBalance() without having to deep dive into the complex SQL code that calculates
the returned value.
Very often, the one reading program code does not need to know, nor care about the detailed logic of called services. On the other hand, if one
needs to deep dive the logic of a service, they always have that option to do so.
In other words, what would you rather debug? A program that does too much and is massive, or a very small program that calls a bunch of
services?
Know Where to Place Your Logic
If you need to add code to fix a bug, or to add functionality, it’s not enough to add correct logic. You must also put that code in the right place. You
might argue that placing that SQL SELECT INTO in a top tier program works, and your unit testing could prove this out, but is that code readable? Is
it better that that functionality or fix be delegated to a lower tier service? Is the share-value of that logic lost?
Easy to Read Code
See the section above called Self-Documenting.
If it takes one longer than 5 minutes to get the jest of a program, to get a feel for what it is attempting to do, then it might not have been written
modularly, nor delegated to lower placed services enough.
Easy to Support Code
Here is how you determine if a solution is easy or hard to support: If it takes a newly hired decent programmer more than 30 minutes to figure out
how an entire solution works, then that solution was probably not coded properly. Now one could argue that all the old-timers have no problem
figuring that code out, but of course they can because they have been there for years.
Only Newbies Decide if Solution Coded Well
So, the best metric of determining if a solution was coded well is to see how long it takes newbies to figure it now; not the time it takes the old-
timers.
Code that is easy to support have the following attributes:
1. Modular
2. Heavy use of Delegation
3. All components and logic are placed in their proper tier of the MTA
4. Services are stateless, loosely coupled, each performing 1 thing
5. Services coded to an accurate Namespace.
Build Upon a Growing Catalog of Services
Overtime, as the catalog of services (microservices) grows within a shop, projects take less and less time to complete, and with fewer and fewer
developers, and less bugs. Over time, a shop that leverages a huge catalog of services can do a lot more projects in less time and costing less
money, requiring less developers, and quality gets better and better.
There are many types of services (APIs) which should be found in a Catalog of Services:
1. RPG/C/COBOL Sub-Procs, Functions and Methods
2. Web Services (provisioned and consumed)
3. Native DB2 SQL Stored Procedures
4. Native DB2 SQL User Defined Functions (UDFs and UDTFs)
We all need to stop reinventing the wheel over and over again!
What does Jeff Bezos (richest man in the world and founder of Amazon) have to say about APIs?


 Taking Advantage of All Server Processors
Our modern IBM i on Power provides multiple CPUs to get the workload done as soon as possible. Sadly, the way solutions have been architected
traditionally for IBM midrange computers has not often enough taken advantage of those multiple processors, nor the ability to do more tasks
concurrently.
Stop Submitting Batch Jobs
For example, jobs are submitted to a batch *JobQ too often. This design pattern sounds simple and effective enough but it’s the worse way to get
units of work done because it serializes the workload instead of multiplexing that work so that it is done concurrently. The problem with submitted
jobs is that each job has to open up the tables, stand up the service programs, and build the cache from scratch. These things take a lot of time and
resources, and if a solution is submitted thousands of times each day, then the system has to perform that over head over and over again
thousands of times.
There are use-cases for submitting jobs, but that list is very short. Consider submitting a batch job once which listens for events, and wakes up
periodically to do processing. Such jobs run 24/7.
Less Synchronous Processing, More Asynchronous
Asynchronous processing is all about loosely coupled components which make up a solution. In other words, keep all components running at the
same time. Do not use serialized logic. Keep the processors working, minimize idle time.
Stop Closing Tables & Cursors
Opening and closing cursors, tables, views, building data caches, and instantiating service programs are expensive and time-consuming tasks. It
would be far better to open once, perform soft closes, initialize the cache once, and instantiate services once, because doing this makes for much
faster execution times, and leverages a cache of database rows which can make the app run faster and faster.
Design Asynchronous Solutions
Instead of using the old traditional tired design pattern of submitting jobs, it would be far better for a program to write a request into a *DtaQ
which is listened to and acted upon by an always running job in the background (a batch job submitted once and runs 24/7). This background job is
loosely coupled to the job that places the request entry in the *DtaQ. This design pattern offers loosely coupled solution, a Separation of Concerns,
and asynchronous processing which would take advantage of concurrency and the multiple processors of the server.
In other words, you want to architect solutions which have:
1. Most Components moving concurrently
2. All Components of solution loosely coupled
3. Virtually no Serialized processing
4. All Moving Components Respect a Separation of Concerns (Soc)
5. One Moving Component can be paused/stopped without effecting the others.
6. The solution is built from the ground up to be scaled.
Build a Bunch of Service Requesters and Service Providers
Apply architectures that provide for programs that make requests, and others that provide services, such that the requests are placed in persistent
*DtaQ’s which are listened to by the Service Providers. There can be exceptions to this direction, but they are rare and infrequent.
When to Use Synchronous Design Patterns
Often GUIs and other UIs require results Realtime (aka NOW). For these requirements, synchronous services must be called. Such services are
Web Services, and services called by UIs with some exceptions.
Keep a bunch of “plates” spinning at the same time...go ahead, the IBM i can handle it!
Taking Advantage of All Server Processors
Our modern IBM i on Power provides multiple CPUs to get the workload done as soon as possible. Sadly, the way solutions have been architected
traditionally for IBM midrange computers has not often enough taken advantage of those multiple processors, nor the ability to do more tasks
concurrently.
Stop Submitting Batch Jobs
For example, jobs are submitted to a batch *JobQ too often. This design pattern sounds simple and effective enough but it’s the worse way to get
units of work done because it serializes the workload instead of multiplexing that work so that it is done concurrently. The problem with submitted
jobs is that each job has to open up the tables, stand up the service programs, and build the cache from scratch. These things take a lot of time and
resources, and if a solution is submitted thousands of times each day, then the system has to perform that over head over and over again
thousands of times.
There are use-cases for submitting jobs, but that list is very short. Consider submitting a batch job once which listens for events, and wakes up
periodically to do processing. Such jobs run 24/7.
Less Synchronous Processing, More Asynchronous
Asynchronous processing is all about loosely coupled components which make up a solution. In other words, keep all components running at the
same time. Do not use serialized logic. Keep the processors working, minimize idle time.
Stop Closing Tables & Cursors
Opening and closing cursors, tables, views, building data caches, and instantiating service programs are expensive and time-consuming tasks. It
would be far better to open once, perform soft closes, initialize the cache once, and instantiate services once, because doing this makes for much
faster execution times, and leverages a cache of database rows which can make the app run faster and faster.
Design Asynchronous Solutions
Instead of using the old traditional tired design pattern of submitting jobs, it would be far better for a program to write a request into a *DtaQ
which is listened to and acted upon by an always running job in the background (a batch job submitted once and runs 24/7). This background job is
loosely coupled to the job that places the request entry in the *DtaQ. This design pattern offers loosely coupled solution, a Separation of Concerns,
and asynchronous processing which would take advantage of concurrency and the multiple processors of the server.
In other words, you want to architect solutions which have:
1. Most Components moving concurrently
2. All Components of solution loosely coupled
3. Virtually no Serialized processing
4. All Moving Components Respect a Separation of Concerns (Soc)
5. One Moving Component can be paused/stopped without effecting the others.
6. The solution is built from the ground up to be scaled.
Build a Bunch of Service Requesters and Service Providers
Apply architectures that provide for programs that make requests, and others that provide services, such that the requests are placed in persistent
*DtaQ’s which are listened to by the Service Providers. There can be exceptions to this direction, but they are rare and infrequent.
When to Use Synchronous Design Patterns
Often GUIs and other UIs require results Realtime (aka NOW). For these requirements, synchronous services must be called. Such services are
Web Services, and services called by UIs with some exceptions.
Keep a bunch of “plates” spinning at the same time...go ahead, the IBM i can handle it!
 Takes Advantage of Concurrency
Solutions which take advantage of concurrency run the fastest, are easiest to support, debug, and understand.
The best way to explain what is meant by Concurrent solutions for IBM i is to talk about one currently running in production:
Takes Advantage of Concurrency
Solutions which take advantage of concurrency run the fastest, are easiest to support, debug, and understand.
The best way to explain what is meant by Concurrent solutions for IBM i is to talk about one currently running in production:
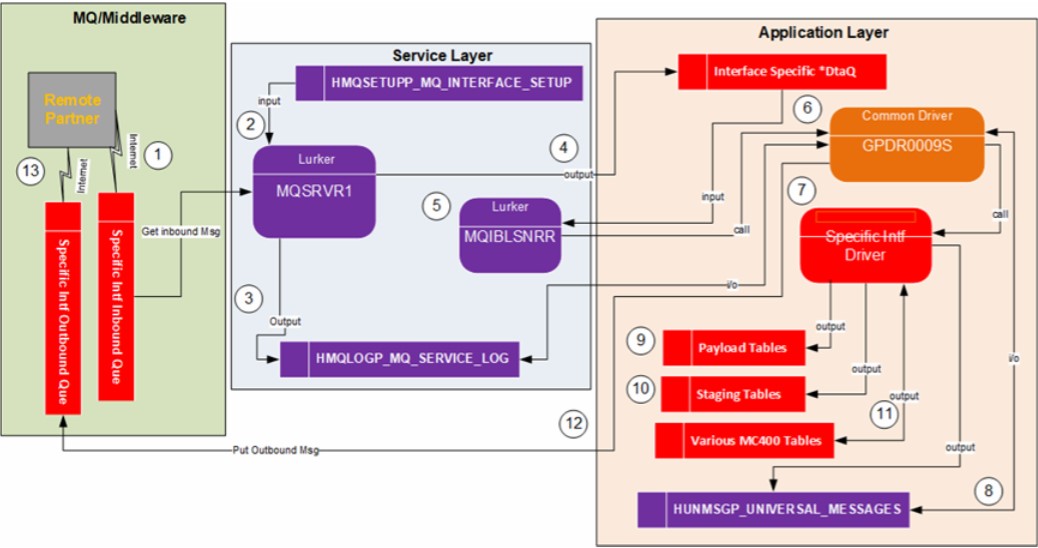 In the DFD (process model) above, this shows the solution for an MQ interface currently running in production. Here is a list of the major moving
parts which are loosely coupled and run concurrently:
1. Remote Partner PUTs Request onto MQ Que
2. Local Listener (Lurker) Listens to MQ Que for Requests
3. Local Listener GETs Requests and place it in Log and *DtaQ
4. Application Listener of *DtaQ processes Request and Returns Response.
Features which make for a very Fast executing Solution:
1. Of the 4 major concurrently running parts, any of them can be paused/stopped without preventing execution of the others.
2. Very little serialized Processing done.
3. The two Listeners (service tier & application tier) are submitted once and run forever in the background.
4. The service programs that support the listeners are instantiated only once.
5. The tables/views used by the listeners are opened once (in some cases soft closes are performed).
6. Data cache instantiated only once.
7. All services, modules, and callers which make up this solution are stateless, loosely coupled, enforced SoC, and a lot of service sharing is
leveraged.
8. Solution is made up of 100s of microservices making support, understanding, maintenance and testing easy.
9. The 100,000+ lines of code across hundreds of services which support this solution are very easy to support, learn, test, debug, and upgrade
with new requirements.
Here is another example of a solution which leverages a bunch of asynchronous process (P159 PoC):
In the DFD (process model) above, this shows the solution for an MQ interface currently running in production. Here is a list of the major moving
parts which are loosely coupled and run concurrently:
1. Remote Partner PUTs Request onto MQ Que
2. Local Listener (Lurker) Listens to MQ Que for Requests
3. Local Listener GETs Requests and place it in Log and *DtaQ
4. Application Listener of *DtaQ processes Request and Returns Response.
Features which make for a very Fast executing Solution:
1. Of the 4 major concurrently running parts, any of them can be paused/stopped without preventing execution of the others.
2. Very little serialized Processing done.
3. The two Listeners (service tier & application tier) are submitted once and run forever in the background.
4. The service programs that support the listeners are instantiated only once.
5. The tables/views used by the listeners are opened once (in some cases soft closes are performed).
6. Data cache instantiated only once.
7. All services, modules, and callers which make up this solution are stateless, loosely coupled, enforced SoC, and a lot of service sharing is
leveraged.
8. Solution is made up of 100s of microservices making support, understanding, maintenance and testing easy.
9. The 100,000+ lines of code across hundreds of services which support this solution are very easy to support, learn, test, debug, and upgrade
with new requirements.
Here is another example of a solution which leverages a bunch of asynchronous process (P159 PoC):
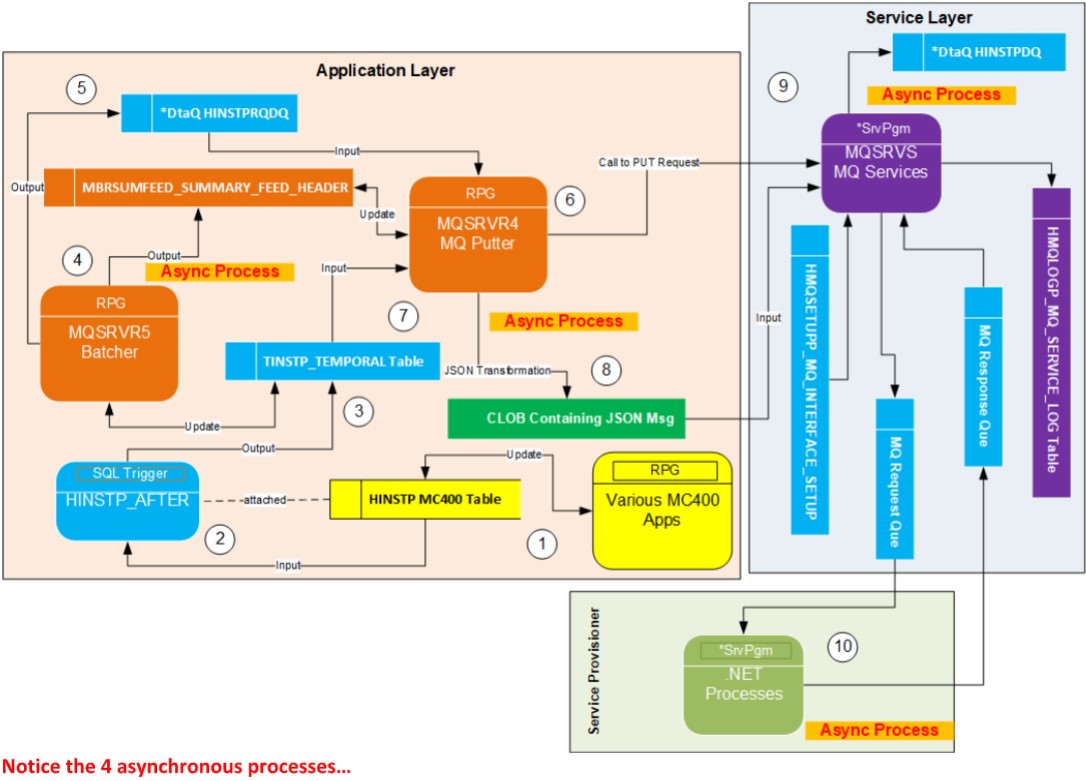 Notice the 4 asynchronous processes…
Scale Up Easily
Solutions should be coded in such a way that if required they can be scaled up for those times when the processing load is great. Solutions which
are scalable are those whose components are less serial, less synchronous, and much more concurrent, more asynchronous.
Let’s explore this example and see what is meant by scalability:
Notice the 4 asynchronous processes…
Scale Up Easily
Solutions should be coded in such a way that if required they can be scaled up for those times when the processing load is great. Solutions which
are scalable are those whose components are less serial, less synchronous, and much more concurrent, more asynchronous.
Let’s explore this example and see what is meant by scalability:
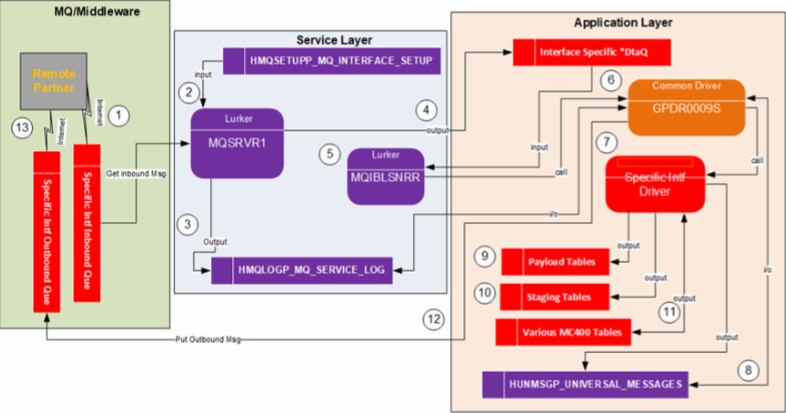 The above DFD is for an existing solution running in production. As you can see it has a lot of moving parts. Two parts are components which are
listening jobs (bullets 2 and 5) that run in the background all the time, waiting for entries in an MQ que or *DtaQ to act on.
In normal times or the year, these two listener jobs (bullets 2 and 5) are sufficient to quickly process requests. But in the fourth quarter of the year,
the number of inbound requests skyrockets causing these listener jobs to get backed up. Processing time slows to a crawl. Users complain.
The system has the option to submit to the background several more listening jobs, and doing so will greatly increase productivity, greatly
decreasing the amount of time requests get processed, and removing the backups of requests. The cost to the overall server responsiveness is
generally minimal when scaling up more and more jobs because listeners go into a sleep mode during those times the ques are exhausted of
requests, when all requests have been processed.
When architecting and coding solutions which are expected to easily scale, one has to be mindful of row locks, concurrency impacts to other
instances (and other jobs), bottlenecks, and not forgetting that each listener instance is self-contained, stateless and does not care if many other
instances of itself are also running.
Such processes need to check the RPG indicator %ShtDn and provide required logic.
Processes can be Easily Snapped On and Off
We want to build modular solutions which are all self-contained, loosely coupled, which enforce SoC and made up of delegated stateless services in
such a way that we can hypothetically replace any component with some other solution easily and reliably, while still maintaining the same
contract. The ability to do this easily and quickly is referred to as snapping on and snapping off pieces of solution which will improve it.
If a solution is coded in the wrong ways, snapping off or replacing pieces of that solution will be complicated, very hard to do, time consuming,
even dangerous to the database.
These are coding mistakes which make it very hard to replace parts of a solution with improvement:
1. Tightly coupled code
2. Code that leaks state beyond the contract (calling parameters), having tentacles (spiderweb/spaghetti) of state coming from here and there
3. Monolithic style of coding solutions
4. Code that blurs the line between the multiple tiers
5. Placement of code in the wrong MTA tier
6. Coding services that do more or less than their assigned Name Space implies
7. Separation of Concerns (SoC) violations
8. Coding services which are Stateful
9. Code which is very hard to read, complicated, not modular enough.
10. Code that does not reference a Namespace.
11. Programs that contain code which belongs in another tier.
The Database is Fully Normalized
Before the construction phase of a project is started, the database must first be designed. If the database is not first designed, the constructed
components will not flow right, nor will they be built correctly.
The tables must be normalized up to at least the 3 rd normal form (3NF) and even through the Boyce-Code normal form when required:
1NF Assign a natural Primary Key (PK), and optionally a 2 nd PK being a unique Identity Value and unnatural. All rows must be uniquely addressable.
2NF Replace repeating groups of columns with a Foreign Key which points to a PK for a row containing those columns in a new table
3NF Identify Transitive Dependencies and break them out into new tables with required FK and PK
BCNF When PK has a Time/Range dimension make sure that range is not overlapped
There are also 4NF, 5NF and 6NF normal forms however applying 1NF through BCNF is nearly always enough.
More information regarding database normalization can be found at this link: Database Normalization. It is the job of the developers to design the
database, not the DBA’s. However, DBA’s double check the DDL for tables to enforce standards, as well as create INDEXes when required.
Who does what?
1. Database Design Developers are responsible DBAs are advisory
2. Tables Developers code the DDL DBAs verify the DDL, modify as required and move to ITG
3. Views Developers code the DDL Developers move to ITG. DBAs have no role for views.
4. Indexes Developers suggest Indexes Only DBAs create the Indexes
Separation of Concerns for DB Development
The reason only DBAs are allowed to place TABLEs in ITG is because they are the last gatekeeper of database normalization, referential integrity,
and business rules constraints, and they prevent junk or redundant tables from littering the database.
The reason only DBAs are allowed to create INDEXes is because too many unneeded INDEXes will slow down overall server response times because
INSERTs, some UPDATEs and DELETEs cause those INDEXes to be maintained.
The reason DBAs oversight is not required for VIEWs is because there is no penalty for the creation of too many views to the overall server
response times; VIEWs are not maintained if they are not open (materialized). Views are not analogous to Logical Files, but INDEXes are.
If a developer needs help with DDL or SQL/PL, fellow developers must be consulted first before reaching out to a DBA.
Proper Placement of Components in Correct Tier
Now that you have read about the many attributes of modern software development, let’s revisit the MTA, and talk deeper about component
placement.
We must code to the MTA, and depending upon the tier, certain types of components are place in each. This table is color-coded to match those in
the MTA diagram above:
Level of Types of Allow SQL Can Access Tables Can Call Components in Types of logic Prone to
Tier Abstraction Components I/O? Directly? which exist in other tiers? allowed level checks? Comments
=========================================================================================================================================================================
The above DFD is for an existing solution running in production. As you can see it has a lot of moving parts. Two parts are components which are
listening jobs (bullets 2 and 5) that run in the background all the time, waiting for entries in an MQ que or *DtaQ to act on.
In normal times or the year, these two listener jobs (bullets 2 and 5) are sufficient to quickly process requests. But in the fourth quarter of the year,
the number of inbound requests skyrockets causing these listener jobs to get backed up. Processing time slows to a crawl. Users complain.
The system has the option to submit to the background several more listening jobs, and doing so will greatly increase productivity, greatly
decreasing the amount of time requests get processed, and removing the backups of requests. The cost to the overall server responsiveness is
generally minimal when scaling up more and more jobs because listeners go into a sleep mode during those times the ques are exhausted of
requests, when all requests have been processed.
When architecting and coding solutions which are expected to easily scale, one has to be mindful of row locks, concurrency impacts to other
instances (and other jobs), bottlenecks, and not forgetting that each listener instance is self-contained, stateless and does not care if many other
instances of itself are also running.
Such processes need to check the RPG indicator %ShtDn and provide required logic.
Processes can be Easily Snapped On and Off
We want to build modular solutions which are all self-contained, loosely coupled, which enforce SoC and made up of delegated stateless services in
such a way that we can hypothetically replace any component with some other solution easily and reliably, while still maintaining the same
contract. The ability to do this easily and quickly is referred to as snapping on and snapping off pieces of solution which will improve it.
If a solution is coded in the wrong ways, snapping off or replacing pieces of that solution will be complicated, very hard to do, time consuming,
even dangerous to the database.
These are coding mistakes which make it very hard to replace parts of a solution with improvement:
1. Tightly coupled code
2. Code that leaks state beyond the contract (calling parameters), having tentacles (spiderweb/spaghetti) of state coming from here and there
3. Monolithic style of coding solutions
4. Code that blurs the line between the multiple tiers
5. Placement of code in the wrong MTA tier
6. Coding services that do more or less than their assigned Name Space implies
7. Separation of Concerns (SoC) violations
8. Coding services which are Stateful
9. Code which is very hard to read, complicated, not modular enough.
10. Code that does not reference a Namespace.
11. Programs that contain code which belongs in another tier.
The Database is Fully Normalized
Before the construction phase of a project is started, the database must first be designed. If the database is not first designed, the constructed
components will not flow right, nor will they be built correctly.
The tables must be normalized up to at least the 3 rd normal form (3NF) and even through the Boyce-Code normal form when required:
1NF Assign a natural Primary Key (PK), and optionally a 2 nd PK being a unique Identity Value and unnatural. All rows must be uniquely addressable.
2NF Replace repeating groups of columns with a Foreign Key which points to a PK for a row containing those columns in a new table
3NF Identify Transitive Dependencies and break them out into new tables with required FK and PK
BCNF When PK has a Time/Range dimension make sure that range is not overlapped
There are also 4NF, 5NF and 6NF normal forms however applying 1NF through BCNF is nearly always enough.
More information regarding database normalization can be found at this link: Database Normalization. It is the job of the developers to design the
database, not the DBA’s. However, DBA’s double check the DDL for tables to enforce standards, as well as create INDEXes when required.
Who does what?
1. Database Design Developers are responsible DBAs are advisory
2. Tables Developers code the DDL DBAs verify the DDL, modify as required and move to ITG
3. Views Developers code the DDL Developers move to ITG. DBAs have no role for views.
4. Indexes Developers suggest Indexes Only DBAs create the Indexes
Separation of Concerns for DB Development
The reason only DBAs are allowed to place TABLEs in ITG is because they are the last gatekeeper of database normalization, referential integrity,
and business rules constraints, and they prevent junk or redundant tables from littering the database.
The reason only DBAs are allowed to create INDEXes is because too many unneeded INDEXes will slow down overall server response times because
INSERTs, some UPDATEs and DELETEs cause those INDEXes to be maintained.
The reason DBAs oversight is not required for VIEWs is because there is no penalty for the creation of too many views to the overall server
response times; VIEWs are not maintained if they are not open (materialized). Views are not analogous to Logical Files, but INDEXes are.
If a developer needs help with DDL or SQL/PL, fellow developers must be consulted first before reaching out to a DBA.
Proper Placement of Components in Correct Tier
Now that you have read about the many attributes of modern software development, let’s revisit the MTA, and talk deeper about component
placement.
We must code to the MTA, and depending upon the tier, certain types of components are place in each. This table is color-coded to match those in
the MTA diagram above:
Level of Types of Allow SQL Can Access Tables Can Call Components in Types of logic Prone to
Tier Abstraction Components I/O? Directly? which exist in other tiers? allowed level checks? Comments
=========================================================================================================================================================================
Application Highest *Pgms, No No Application No heavy complex No Application
Orchestrators, Presentation detailed logic. Only components
Drivers, often service calls, logic abstract services,
Options, rately like If, Do, Until, and delegate to
*srvPgms Do While, Loops, services, and sometimes
Iterations. Presentation components.
Presentation Highest *Pgms, often No No Presentation No heavy complex No Presentation components
Menu Options Application detailed logic. abstract services,
controlling statements and delegate to
like If, Do Until, Do services, and sometimes
While, Loops, Iterations. Application components.
Logic primarily to
respond to human
(user) inputs and
navagations.
Service Medium *SrvPgms, No No Service Heavy complex No Service
Stored Procs, Data-Access detailed logic to componentract
UDFS, rarely enforce business Data-Access components
rules, calls to Data- and delegate to Data-Access
Access services for components.
data extraction, and
data processing (*1 CRUD)
Data-Access Low/Medium *SrvPgms, Yes No Data-Access Minimally Data-Access components
Stored Procs, Views abstract Views and geth their
UDFs, Triggers, data from Views.
*Pgms
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Views Low SQL VIEWs No Yes Views n/a Views abstract the tables
Tables
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Tables Very Low SQL TABLEs No Yes Tables (referential integrity) n/a Tables are Sacrosanct and can
only be direclty referenced by
views.
1 CRUD stands for row CReation, Update and Delete.
Glossary
Term Definition
=================================================================================================================================================================================
Abstract In the context of software, abstract components are objects which represent concrete logic, and processes.
Abstract objects delegate tasks and details to concrete objects. Abstraction is the act of hiding, encapsulating
complex and/or detailed processes.
Activation Within the context of executables on IBM i, the act of loading and initializing a program into RAM, and into an
Activation Group.
Activation Group An activation group is a subdivision (logical boundary) of a job that ILE enlists to keep track of resources a program
uses. One job can have several activation groups in use simultaneously. Each job has their own activation groups
which are separate from other jobs. An activation group is not an object, but rather a grouping of resources within
a job.
Agnostic In the context of software, a solution is said to be agnostic if it does not care about certain attributes of callers.
There are degrees of agnosticism. For example, an exposed web service may not care if the caller is from the
trucking industry, or healthcare industry, or any particular industry. It may not car what platform the caller is
from, or what language the caller code is written in.
API Application Program Interface. This is a loosely used term, but in general an API is a service that provides
functionality to an application or solution.
Application Layer The Application layer or tier is where application related components are placed. This is the top layer of the Multi-
Tier architecture.
Asynchronous A process is said to be asynchronous if steps in the process are (1) running concurrently, and (2) are triggered by
an event. Such processes are said to be concurrent. Web Services are not Asynchronous, but MQ interfaces are.
AxisC An IBM i product that comes with the OS. It is used for consuming web services from RPG, COBOL or other HLL. It
is a C++ library and is known for fast execution and robust support of the full HTTP protocol. At BERKADIA, this
product is wrapped with our own RPG service program AXSRVS.
AXSRVS An RPG service program that wraps the C++ functions in a C++ library called AxisC.
Binder Source Binder source is used during the creation of a service program. It tells the compiler which services are to be
exported. Once an executable is created, the binder source is not needed to run the program.
Binding Directory A Binding Directory is a list of service programs and modules that will be bound into an executable (*Pgm or
*SrvPgm). It tells the compiler where these resources can be found. Once an executable is created, the binding
directory is not needed to run the program.
Business Rule A business rule is a rule that defines or constrains some aspect of business and often resolves to either true or
false, or returns a value based on following defined rules. Business rules are intended to assert and enforce
business structure or to control or influence the behavior of the business.
In the context of computer systems, a business rule is codified in a computer language as a set of coded
statements.
If a business rule is being coded in a computer language, that code must be placed in a service (sub-procedure,
method, function, service, stored procedure, UDF).
Caller A caller is simply a process that calls a service. Usually a caller is a stand-alone app, but it does not have to be.
Often times a service can be a caller too, because it can call other services. Other names for Caller are Client, and
Client-Caller.
CBSE (Component Based Software Engineering)
CBSE is a programming architecture similar to traditional modular, however the difference is that with CBSE,
modules are encapsulated and self-contained services (components).
Change Control A Change Control system is a system that directs, tracks, protects, and enforces rules during the promotion of
software across various environments. The current change control system at CuraScript is TurnOver.
Client See the term Caller.
Client-Caller See the term Caller.
Commitment-Control An industry standard that treats all the table updates for a given process as one atomic process. Commitment-
Control insures that the entire process happens or does not happen at all; will not allow the process to be done
partly. Its all or nothing.
Component A component is an object that makes up a software solution. Such objects are tables, views, programs,
procedures, services, *DtaQ’s, *DtaAra’s, to name a few.
Concrete In the context of software, concrete objects are where the atomic logic is placed; the logic that does the actual
task.
Constraint In the context of a database, a constraint is defined to a table and limits how a row or column can be valued, and
can also define how tables relate to each other. There are 5 kinds of constraits: NOT NULL, DEFAULT, CHECK,
PRIMARY KEY, and FOREIGN KEY.
Consuming In the context of web services, consuming is when a process calls a web service. In other words, those that call a
web service are consuming that service. See Provisioning.
Content-Type One of many HTTP Request Headers.
Contract In the context of software, the contract is the requirement for calling a service, through which a caller passes its
state to a service.
Contract A contract is the parameter list of a service. It’s a contract because it is enforced either at compile time and/or at
execution time. A contract makes sure services are called with the right parameter types and values.
Controller In the context of MVC, the controller are the programs that make up a solution.
Controller See the term MVC.
Data Access Layer The Data Access layer or tier is where programs that extract data and process data found in the database tables via
views.
Data Layer The data layer is where data services are placed. The data layer is where interfaces to the database (model) are
kept.
Data Service A data service is a service that process, retrieves, or sets data for a caller. In the MVC design pattern, data services
should only exist in the Model (data layer).
Data services are always written as one or more of the following, and in the order of most preffered to least
preferred:
1. Native or External User Defined Table Functions
2. Native or External User Defined Functions
3. Native or External Stored Procedures
4. SQL VIEW
Data services can also be wrapped as Web Services.
Data Structure A data structure is an RPG construct that is built by stacking fields of various types and lengths together into a unit
of data. A DS is analogous to a record, however its fields can overlap. Passing and receiving data structures should
be avoided when calling programs and services, and using with SQL statements.
Data Studio Data Studio is a free GUI IDE that is based upon Eclipse. It can be integrated in RDi. Data Studio is a very powerful
workbench for the developing DB2 applications, as well as administrate DB2 databases.
Data-Centric A data-centric system is a system that centralizes all business rules inside the database.
Database Tier The Database Tier is where tables, views, and data-access programs are placed. The Database Tier is made up of
3 sub-tiers: DAL (data-access layer, views and tables).
DB2 IBM’s Database Management System (DBMS) which runs on all IBM platforms including Windows, MacOS, un
DB2 DB2 is the brand of RDBMS offered by IBM and across all IBM platforms and OS’s. DB2 is the #1 commercial-grade
RDBMS in the world (in features and performance), and 2 nd in commercial sales, to #1 Oracle.
DB2 runs on ALL non-IBM platforms such as Apple Mac OS X, HP, Windows, Linux, UNIX, and Mainframes, and can
be accessed from any device that can connect to DB2.
Across the DB2 RDBMS offerings, there are just 3 major flavors: (1) DB2 LUW (Linix, UNIX, Windows), (2) DB2 IBM
i, and (3) DB2 zOS.
Although DB2 zOS has run on mainframes since the early 1980’s, LUW recently runs on Mainframes, and is
superceding DB2 zOS, which leaves just two major flavors going forward: LUW & IBM i.
As time goes on, LUW and IBM i are coming closer and closer together, and one day they will both be the same, or
very similar.
Moving a DB2 LUW database from or between any of these: Mainframe, Windows, Mac, HP, Linux, UNIX does
NOT require any changes to the code. LUW makes the promise of Write Once, Run Anywhere, a claim that even
Java cannot truly make.
Moving a DB2 database between any of the machines that run LUW and IBM i is like translating from British
English to American English; although a little big different, they are similar enough to make such a migration easy.
It is this reason that many IBM i shops are pivoting toward using DB2 SQL/PL for their new developments. This
pivot secures their future because doing so no longer makes their enterprises dependent upon the future of IBM i.
DBA Database administrator. A DBA administrates the data.
DBE Database Engineer. A DBE develops SQL apps.
Decoupled In the context of software systems, decoupled is the state of a system when its code base is not directly coupled
with it’s data base. Decoupling the code base from the data base is the direction CuraScripts is going.
Delegation In the context of software, delegation is the act of delegating a task to a service. In this regard, a program does
not contain detailed and atomic logic to perform a certain service, however it does call a service that has that
atomic logic. In this way, a program delegates a task to a called service.
Deploy In the context of web services, when a service is made available to callers, it is said to be deployed. To deploy a
web service is to make it available to callers.
Deterministic A Stored Procedure, UDF, or UDTF can be created as deterministic with the keyword DETERMINISTIC. This
keyword causes the input and output pairs to be cache’d so that performance can be greatly improved.
Not all stored procedures, UDF’s and UDTF’s are good candidates for deterministic processing.
DFD Data Flow Diagram. DFD is often called a Process Model. A DFD is not a flow chart, but rather a map of how
services, process, and data stores relate and are processed. A DFD shows process flow, where a flow chart shows
logic.
Embedded SQL There are several languages that allow SQL to be embedded in their code statements. The type of SQL statements
allowed to be embedded is usually a subset of the entire SQL command offerings.
Encapsulation Within the context of software, logic is said to be encapsulated if it is placed in a service.
Encapsulation Encapsulation is the idea that program or service is limited only to the local resources within it, and its parameter
list. A truly encapsulated service or program uses no global or shared resources with other services or programs.
ERP Enterprise Resource Planning system. Enterprise resource planning (ERP) is business process management
software that allows an organization to use a system of integrated applications to manage the business and
automate many back office functions related to technology, services and human resources.
Export In the context of software, a service is said to be exported if its exposed to external callers.
Exported In the context of services, an exported service is a service that can be called by callers. In contrast, an internal or
private service can only be called by the service program it exists in.
External DB2 Object Objects written in a language other than native DB2 SQL/PL, and which are wrapped as DB2 objects. At CuraScript,
external DB2 objects are written in RPG.
FK Foreign Key. A FK is made up of one or more columns that point to the PK in another table.
Function A Sub-Procedure in RPG. See the term Service.
GET GET is one of the many HTTP methods. GET is a type of web service that returns a list of information to a caller.
Global Resources which are outside any procedure, yet are shared by all procedures contained in a module. Global
resources are to be avoided as much as possible.
GUID Stands for Global Universal ID. Microsoft invented this term. IBM has the same thing but they call it a UUID.
GUIDs are guaranteed to be unique 36 byte values across time, past, present and future, and across all computing
devices. Because of these attributes, GUIDs are ideal for giving things unique identifiers.
Helper In the context of software, a helper is a private service found in a service program that is not exposed however its
role is to support other services.
HTTP Client A process that consumes a web service.
HTTP Client App A process that provisions a web service
HTTP Headers Properties about an HTTP request and response.
HTTP Method A verb which is assigned to a web service such as GET, PUT, POST, DELETE, PATCH, and others.
HTTP Status The status which results from a call of a web service. Each call of a web service provides two of these HTTP
Statuses; one at the system level and a 2 nd one at the application level.
IBM i The name of one of the OS’s which runs on the IBM Power Systems server. The other OS is IBM Linux.
IBM i IBM i is not hardware. IBM i is an OS which has its origins in OS/400. The only hardware that IBM i runs on is
Power Systems server. CuraScript’s TPS ERP runs on IBM i and on a Power Systems server.
ILE Integrated Language Environment. ILE is a framework provided by IBM i, which when coded to will allow programs
to be created by binding modules of services together.
Imported Services can be imported to a caller when the service program those services exist in is bound to a caller. Because
those services do not exist in the caller, they are said to be imported.
INDEX An INDEX is a DB2 SQL object. INDEXes are similar to DDS Logical Files, and although they are labeled *FILE/LF the
are not LF’s. INDEXes do not support multi-members. Like LF’s, INDEXes are maintained all the time, regardless if
they are open or not.
Internal (private) Services that can be called only from other services within the same program or service program are said to be
internal or private services. Callers have no visibility to internal services.
iSeries An obsolete legacy system that has not been manufactured in over 8 years. CuraScript does not use an iSeries.
See the term IBM i.
IWS Integrated Web Service. This is an IBM i product that comes with the OS. I provides RPG and other HLLs the ability
to provision and consume web services.
Journaling An industry wide feature that logs all changes to tables. Depending upon how its set up, journaling can log only
after row images, or both before and after images. Journaling is required for Commitment-Control, but there are
other excellent reasons to journal such as for triage support of applications, debugging, and anytime one needs to
track what program changed what tables at what date and time and by what user.
JSON Java Script Object Notation. This is a universal industry-wide common format for exchanging data between
disparate computer platforms, Oss, languages, and processes. JSON adoption allows any computer program to
easily interface with any other. JSON is fantastic to use because it is agnostic to a computer’s OS, language,
platform, and type.
JSON Key Data is carried in JSON in Key/Value pairs, where the Key is the name of that value (similar to column name, field
name).
JSON Object One of the types of JSON notation. An object is a container of 1 or more JSON Key/Value pairs.
JSON Value A JSON Value corresponds to a JSON Key. JSON Value is the data for that key.
JSON Verifier & Prettier App There are many online and desktop apps that allow you to paste in JSON for verification and to make it pretty for
humans to read.
Listener In the context of software, a listener is a program that runs in the background and listens to a que or waits for an
event to trigger processing. Sometimes a listener program is called a Lurker.
Local Resources which are found inside a procedure. The creation and use of local resources is greatly encouraged.
Loosely Coupled A process is said to be loosely coupled if it is stand-alone, agnostic, independent, self-contained, and respects a
separation of concerns between it and other processes it relies upon.
Lurker See the term Listener.
MAIN In the context of computer programs, a MAIN procedure has a *Entry point which allows it to be called directly
from other programs and services without the need to bind it to callers. In contrast to MAIN, there are NOMAIN
procedures.
Method A Sub-Procedure in RPG. Could be a Stored Procedure or UDF of UDTF in DB2. Could be a Web Service. See the
term Service.
Microservice A Microservice is a function deployed as a web API which does 1 atomic thing, like return customer name, or
validate P/O number. It by itself is not an application or service, but it is called by these.
Model In the context of the MVC, the model is the database.
Model See the term MVC. The Model is also knows as the Data Layer.
Modularity In the context of software, a solution is said to be modular if it is coded in such a way that logic is encapsulated in
many services, which are often shareable. This term is fairly loose and is applied to many things in software.
Module In the context of ILE, a Module contains 1 or more procedures. Modules are either Cycle, MAIN or NOMAIN.
In the case of CYCLE-MAIN modules, a module contains 1 *Entry procedure and 1 or more other procedures
referred to as sub-procedures, and the RPG cycle logic is present. In the “H” spec these keywords are not
specified: MAIN, NOMAIN.
For LINEAR-MAIN a module contains 1 main entry point, and 1 or more sub-procedures (no RPG cycle logic). In the
"H” spec MAIN is specified.
In the case of NOMAIN modules, this module contains 1 or more procedures, and each of these are referred to as
sub-procedures because none of them are *Entry’s. In the “H” spec NOMAIN is specified.
Monolithic Software is said to be monolithic if it is written in such a way that solutions are coded with one or a few massive
programs each that do too much. Monolithic solutions are very loosely coupled, do little or no delegation, and the
few components making up the solution cannot be cleanly mapped to MTA or MVC architectures. Sharing of
services are not possible.
Monolithic An outdated style of writing computer code, that makes a monolithic program do many tasks directly. Monolithic
programs are often very big, and unwieldy, hard to support, debug, and maintain. This style of coding must be
avoided, and instead a style that codes to the design patterns SOA and MVC must be used.
MQ MQ is an IBM product which provides a very high-speed data que which can be read and written to by local and
remote processes. MQ supports Asynchronous interfaces in contrast to web services that support Synchronous
interfaces.
MTA See Multi-Tier Architecture.
Multi-Tier Architecture A software architecture that places components into their rightful tier. The tiers are from top to bottom:
Application Tier, Presentation Tier, Service Tier, Data-Access Tier, VIEW Tier, and TABLE Tier. The last 3 Tiers are
known as the Database Layer aka the Model.
MVC A design pattern at the program and solution level that places the components of a software solution into their
rightful layer. MVC is an acronym for Model, View, and Controller. MVC components can be mapped to MTA
which provides more granularity.
MVC MVC stands for Model, Viewer, and Controller. MVC is a design pattern that was discovered 30+ years ago, but is
recently coming into popularity in the IBM i space.
Model, Viewer, and Controller are the three layers that make up a modern application.
The Model layer is made up of data services, and of the three layers is the only layer that accesses the database
directly. The model is also referred to as the Data Layer.
The Viewer layer supports all UI’s, and all Human-Interfacing communications (emails, texts, pdf’s, reports,
dashboards) and is responsible for the UX. Viewers never access the database directly. Viewers depend upon data
services in the Model layer to get and process data.
Controllers are callers that direct and control business logic. They do not define business logic, nor provide code
that contains business logic, however they control, delegate, and control services that contain the actual business
logic. Controllers never access the database directly. Instead Controllers will call data services that get and
process the data for the Controllers.
Name Space A Name Space is a name assigned to service such that the name exactly describes what the service does. Often
such services wrap one or more complex services. Name Space coding allows the code to read more like plain
English which makes the code more readable, easier to support and learn.
Natural PK A natural Primary Key is one that is made up of one or more columns that represent business entities or business
nouns. In contrast to Natural PKs, Unnatural are always made up of one Identity Column. It is preferred all tables
be assigned a Natural PK, and if this cannot be done, then at a minimal an Unnatural PK must be assigned. Ideally
both types of PKs should be assigned.
Navigator i Navigator i is a GUI app that allows one to operate, maintain, develop, and fine-tune an IBM i system. Navigator is
very helpful with SQL development because it can suggest ways to improve query performance, as well as manage
DDL, DML, and DCL code. See the term Data Studio.
NOMAIN A NOMAIN module contains 1 or more services which must be bound to a caller if the caller wants to call them.
NOMAIN services cannot be called without first binding to the caller. See the term MAIN to see contrasts.
Normal Forms In the context of database, the normal forms are rules which should be applied to the design of a database so that
it can reach the state of being normalized. These rules are named 1NF, 2NF, 3NF, BCNF, 4NF, 5NF and 6NF. These
rules were defined by IBM researchers Edgar F. Codd, and Chris J. Date back in the 1970s.
Obfuscate To hide. To mask. Revealed to those who need to know, hidden from those who don’t.
OPM Original Program Model. This is an outdated framework for coding RPG and it must be avoided because it
executes slow, and does not offer much sharability between modules. A better framework to code to is ILE.
Overloading Overloading is the concept of creating more than one service that share the same name. Their only differences
are (1) their signatures (parameter list), and (2) their Specific Names. Creating several services with the same
name allows a business rule to be called in different ways. Often all overloaded services having the same name
call the same core service. In this way, logic is not duplicated.
Paging In the context of web services that return information such as GETs, a specified page of data is returned instead of
the entire result-set. When a web service returns a page at a time of data, response time is greatly improved, and
the caller only gets as much data as it requires.
Parameter List See the term Parm List.
Parm List A parameter list is a list of input fields, output fields, and input-output fields required to call a program or service.
Payload In the context of web services, a payload is a container. There are two payloads associated with each web service
call for methods POST, PUT, and PATCH. The first being the request payload and the 2 nd is the response payload.
The other HTTP methods provide only the response payload.
Payload Body The container of JSON for a request or response.
PgmInfo In RPG, a control specification value that is required for wrapping RPG services programs as web services with IWS:
PgmInfo(*PCML :*Module :*DclCase :*V7);
PI Procedure Interface. A PI is the implementation of a service.
PK Primary Key. A PK provides a unique handle for each row in a table. There are two types of PK’s. Natural PK and
Unnatural PK.
PL DB2 SQL Procedural Language. All native DB2 processes (stored procedures, UDFs, UDTFs and Triggers) are written
in PL . All major platforms have their own version of PL. Oracle calls theirs PL/SQL, DB2 calls theirs SQL/PL, and
Microsoft calls theirs T-SQL. All versions of PL are similar in syntax and features. It is better to create data services
in PL because PL can be easily ported to other systems. In contrast, data services written in RPG cannot be easily
ported to other systems.
POST An HTTP method used for processes that insert rows in a table.
Postman One of many desktop apps which are known as HTTP clients. It allows a user to call web services.
Power Systems This is the name of the hardware, the server that runs the IBM i OS.
PR Prototype. A PR defines the signature of a service. When a PR is coded properly, one need only look at a PR to
know what the service does and how to call it; without looking inside the PI (service implementation).
Presentation Layer The Presentation layer or tier is where UI components are placed. This is the 2 nd from the top tier of the Multi-Tier
Archtecture.
Procedure A procedure is RPG code contained in a module. It can be a stand-alone MAIN *Entry procedure which compiles
into a *PGM, or it can be one of many other procedures. A procedure can be a sub-procedure if it is not a MAIN
*Entry type. See term sub-procedure.
Procedure Interface See the term PI.
Prototype See the term PR.
Provisioning To provide a web service for others to call.
PUT An HTTP method used for processes that update rows in a table.
Query Query refers to a part of any SQL statement that specifies the extraction of a list of rows. Usually queries take the
form of an SQL SELECT statement.
Query String Input parameters specified in the URL for a web service. HTTP methods such as GET and DELETE use query string.
It is preferred that query strings not be used, and in favor of methods that provide a proper request body for a
payload.
RDBMS Relational Database Management System. DB2 is an RDBMS, as is MySQL, Oracle and many others.
Record Level Access See the term RLA.
Redeploy To redeploy a web service is to refresh its executables. When RPG that supports a web service is changed, often
times the service must be redeployed, especially if the change was done in a supporting service program.
Refactor The act of modifying existing computer code to improve performance and manageability, without changing the
behavior and logic.
Remote Caller A remote consumer of a web service
Remote Partner Another name for Remote Caller.
Request The input parameters for a web service.
Request GUID Each request must contain a Request GUID value to uniquely identifies that request.
Requester The consumer of a web service.
Responder The provisioner of a web service.
Response The response a web service provisioner creates for a request.
Response GUID Each web service response is assigned a Response GUID value that uniquely identifies that response.
RLA Record level Access. RLA is the processing of data a record at a time. See the term Set Processing to see how RLA
contrasts. RLA should be avoided unless absolutely required. Set Processing is the better way to go.
RPG RPG is a modern procedural language that runs on just one OS and Server: IBM i on Power.
The latest version of RPG is called Free RPG, and is not considered legacy, but rather is a modern language for
business.
When coded to the ILE framework, RPG can provide some features of a true OOP language, however RPG is not an
OOP language. The great benefit of RPG is that (1) code can be encapsulated into services, (2) the scope of each
service can be limited to local resources only, (3) services can be bound and shared by many executables, (4) Free
RPG is very easy to read, reading like plain English, (5) services can have parameter lists which are enforced at
compile-time, and (6) RPG executes faster; just as fast as C code, and much faster than any OOP language.
RPG can be wrapped as a DB2 External Object: Stored Procedure, UDF, and UDTF. RPG can also be wrapped as a
SOAP or RESTful Web Service. SQL code can be embedded in RPG.
Self-contained In the context of software, a service is said to be self-contained if all the resources it requires is found within the
service and its contract (calling parameters). The service requires only local resources, never global resources.
Separation of Concerns Separation of Concerns is the placement of programs and services in one of these 3 layers: Model, Viewer,
Controller. See the term MVC.
Separation of Concerns (SoC) The concept of a process respecting its concern in processing, in that it only performs tasks it is concerned. Such
concerns can be presentation, application, services, data-access, and database.
Service In the context of Web APIs, a service is simply a Web API. But a service can also be an RPG Sub-Proc, a function,
method, and microservice.
Service Can be a Sub-Procedure in RPG, a Stored Procedure, a User Defined Function, a User Defined Table Function, a
Web Service. Other names for service are Method, Sub-Procedure, Function.
Service Account A UserID and Password combination created specifically for a web service to use. These accounts are assigned to a
web service, and not a human.
Service Layer The Service Layer or Tier is where service components are placed.
Service Program A Service Program is a multi-entry-point executable that is created by binding together modules and other service
programs. A Service Program contains 1 or more services which are called by callers that are bound to the service
program.
Set Processing Set Processing refers to the treatment of a set of table updates as one atomic process. In contrast, RLA or Record
level Access is the processing of data at the record level. Set Processes encapsulate and hide the implementation
required to perform the required table updates. RLA exposes that implementation to a caller. Usually set
processing uses a fraction of the number of statement over using RLA. Set processing usually executes faster than
RLA.
Signature In the context of a service, a signature is the combination of service name, and parameter list.
SOA Service Oriented Architecture. The concept of thinking of everything as a service. SOA refers to a concept and not
a particular implementation.
SOA Service Oriented Architecture. SOA is a design pattern. The spirit of SOA is Everything is a Service.
SQL/PL DB2’s robust procedural language used for coding Stored Procedures, User Defined Functions, and Triggers.
SQLSRVS A service program that provides SQL feedback services.
Stateful A process is said to be stateful if it remembers the state of its resources between calls to it.
Stateless A process is said to be stateless if it forgets the state of its variables between calls to it.
Stored Procedure A Stored Procedure is a DB2 database object program. A Stored Procedure can be called by any local or remote
device regardless of it’s language, OS, Platform or server. Any caller running on any device can call a Stored
Procedure so long as it can get a connection to DB2.
There are two types of Stored Procedures: Native and External.
External Stored Procedures are written in a language other than the native DB2 SQL/PL language. One example of
an external Stored Procedure are those written in RPG.
Sub second Response A noble goal of all developers who create web services. The processing of the request and response is measured
in less than 1 second in the milliseconds.
Sub-Proc An RPG sub-procedure, may also referred to as a method, function, microservice and service.
Sub-Procedure A sub-procedure is a procedure. What makes a procedure a sub-procedure is that it is called from a main
procedure. Sub-procedures can be found locally in a caller, or in a Service Program. In other words, a sub-
procedure is subordinate to a main *Entry procedure.
Other names for Sub-Procedure are: Methods, Services, Functions.
See the term Procedure.
Sub-Query or Sub-Select A sub-query is a query embedded inside a main query. A SELECT statement that is embedded inside another
SELECT statement is referred to as a sub-query.
Subroutine An outdated construct that partitions global logic into a routine, which can be called from many points of a
program. Most modern languages do not offer this type of construct. A better way to partition logic is the use of
Sub-Procedures.
Swagger An industry-wide list of web service properties placed in JSON format. A Swagger contains pertinent information
about a web service, especially valuable to those needing to call a web service.
Synchronous A process is said to be synchronous if its steps are sequential and called inline. Such processes are said to be serial.
TABLE A TABLE is a DB2 SQL object. It is similar to a DDS Physical File, however TABLEs do not support multi-members.
TABLEs are not PF’s even though TABLEs and PFs are both labeled *FILE/PF. TABLEs do much more than DDS PF’s.
However their usage in SQL statements is usually interchangeable.
Table Layer The Table layer or tier is where the tables which make up a database are placed. The Table layer makes up the
bottom tier of the MTA.
Tightly Coupled Solutions are said to be tightly coupled if their components are dependent upon others, their states spread
outside their contract, their usage is very specific to certain callers, and they do not respect a strict separation of
concerns.
Traditional Modular A type of programming architecture where logic is split out into other programs and subroutines. This architecture
contrasts with CBSE modules, which are encapsulated and self-contained services (components). See CBSE.
UDF User Defined Function. A UDF is a DB2 database object function. Like a Stored Procedure, UDF’s can be called by
any device so long as it can get a connection to DB2.
UDF’s usually return a value, and can be called from HLL’s, and from other SQL statements such as queries. UDF’s
can be called from IF statements, and can be used as parameter values.
UDTF User Defined Table Function. A UDTF is similar to a UDF, however a UDF returns a scalar value, and a UDTF returns
a TABLE. See the term UDF.
UI User Interface
UMSRVS An RPG service program that provides services in support of all things Universal Messaging
Unnatural PK An Unnatural Primary Key is one that is made up of just one column which is an Identity. Unnatural PKs are ideal
for fast joining of tables. Tables assigned an Unnatural PK must also be assigned a natural PK if at all possible.
Unnatural PKs alone are usually not sufficient, and this is why an Unnatural PK must also be assigned to each table.
User Defined Function See the term UDF.
User Defined Table Function See the term UDTF.
UTSRVS An RPG service program that provides miscellaneous services, utilities.
UUID See GUID.
UX The User Experience provided by UI’s.
VIEW A VIEW is a DB2 SQL object. VIEWs are similar to DDS Logical Files, however VIEWs are not LF’s even though both
are labeled as *FILE/LF. VIEWs do not support multi-members, nor can one add a key to a VIEW as is the case with
LF’s. However an order can be specified for VIEWs by using a sub-query. VIEWs are not maintained unless they
are open. VIEWs can be built over other VIEWs.
View Layer The VIEW layer or tier is where SQL VIEWs are placed. These objects are the only ones that can reference tables
directly. Viewer In the context of MVC, the viewer is the presentation layer. Viewer See the term MVC.
Web API Another name for Web Service.
Web Service A function that is deployed to the internet, and is assigned a URL.
Web Service A web service is service that is OS/platform/language/server-agnostic because any process running on any thing
can call them so long as the process has an internet connection.
Web Services are built to transport data in the form of XML, or JSON, and can adhere to the SOAP or REST
protocols.
Web Services often wrap existing data services written in RPG, PL and other IBM i languages.
Web Service Server A WSS server which supports, coordinates, and handles web service calls for provisioned services. A WSS Server is
a logical container of services.
Wrap The process of wrapping a local service so that that service can be evoked by more types of callers, external and
local. For example, an RPG sub-procedure can be wrapped as a DB2 object, which allows that sub-procedure to be called
as if it were a native DB2 stored procedure or UDF. If that same RPG service is wrapped as a SOAP or RESTful
service, it can be called by any web process, making it a Web Service.
Wrapper In the context of software, a wrapper is a service that provides an abbreviated interface to a more complex
service. Wrappers are ideal for placing functionality in a custom Name Space. A wrapping service is said to
obfuscate the working of the services being wrapped.
WSS See Web Service Server.
End of document.